Most people think the internet is just what they see: Google searches, social media feeds, news websites, and online shopping. But what you browse every day is only a tiny fraction of what actually exists online.
Beneath the familiar surface lies a much larger, mostly invisible world, one that’s widely misunderstood, often misrepresented, and rarely explained clearly. Terms like deep Web and dark Web get thrown around interchangeably in news headlines and crime documentaries, but they are not the same thing. Not even close.
Understanding the difference between the deep Web vs dark Web vs surface Web isn’t just a tech curiosity; it’s fundamental digital literacy. Whether you’re concerned about online privacy, heard about data leaks on the dark Web, or simply want to understand how the internet is really structured, this guide breaks it all down in plain language.
What Is the Surface Web, Deep Web, and Dark Web?
The internet is not a single, flat space. It’s structured in layers, and most people interact only with the very top one. To truly understand the deep Web vs dark web debate, you first need to see the full picture of how the internet is organized.
The Three Layers of the Internet Explained
Think of the internet as a building with three floors. Most people spend their entire lives on the ground floor, never realizing there’s far more above and below.
The Surface Web is the ground floor. It’s everything publicly accessible and indexed by search engines like Google, Bing, or Yahoo. If you can find it by typing a search query, it lives here. News sites, YouTube, Wikipedia, e-commerce stores, all surface web.
The Deep Web is everything above the ground floor, the vast, password-protected interior of the internet that search engines simply cannot index. Your Gmail inbox, your bank account dashboard, your Netflix profile, private company databases, none of this appears in Google search results, and that’s entirely intentional.
The Dark Web is a deliberately hidden, encrypted corner of the internet that requires special software to access. It’s not indexed, not accessible through a regular browser, and designed specifically for anonymity. It sits within the deep Web but operates very differently from it.

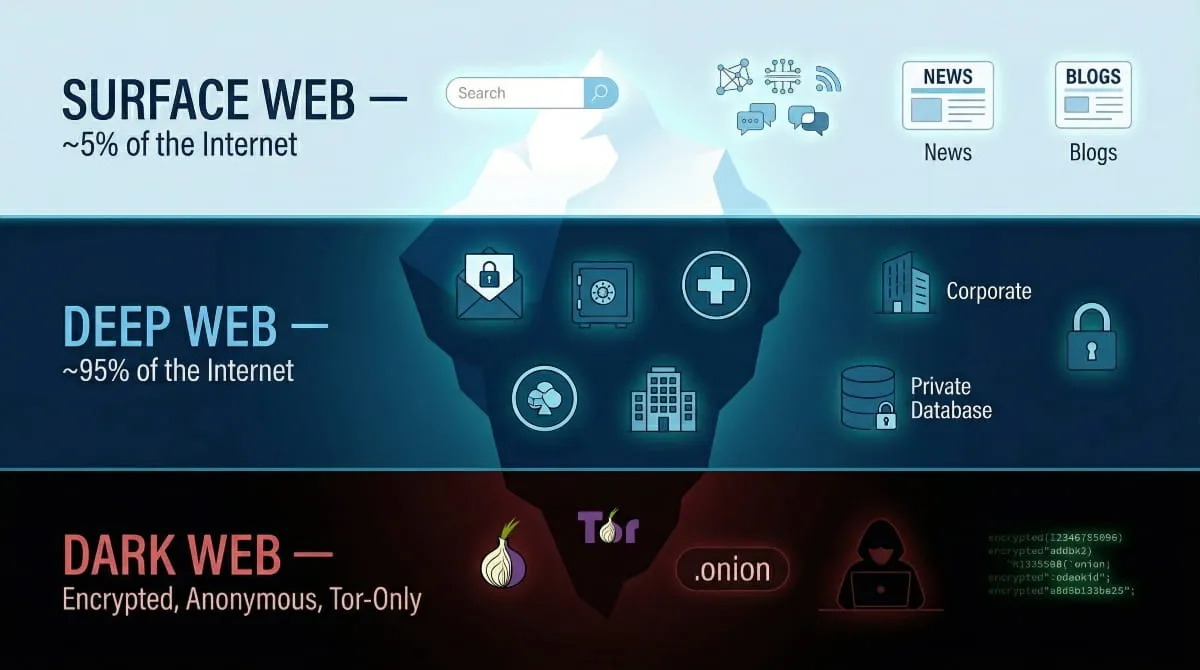
The Iceberg Model: Why Most of the Web Is Hidden
The most accurate way to visualize this is the internet iceberg.
The surface web, everything you browse daily, represents just the tip above the water. Estimates suggest it accounts for less than 5% of the total internet. The deep Web comprises the vast body beneath the surface, accounting for the overwhelming majority of online content. The dark Web sits at the very bottom: small in size, but deliberately concealed and only reachable through specific tools like the Tor browser.
The iceberg model explains why so many people are shocked to learn how little of the internet they actually see. It’s not that the rest is hidden for sinister reasons; most of it is simply private, protected, or purposely restricted from public indexing.
Before going deeper, here’s a clean baseline to anchor everything that follows:
- Surface Web, publicly accessible, indexed by search engines, visible to anyone with a browser
- Deep Web, not indexed by search engines, but perfectly legal and used by billions daily
- Dark Web, A small encrypted network within the deep Web, accessible only through anonymous browsers like Tor
These three layers aren’t competing versions of the internet; they’re all part of the same network, just operating at different levels of visibility and accessibility.
What Is the Deep Web?
The deep Web is probably the most misunderstood part of the internet, not because it’s complicated, but because it sounds mysterious when it really isn’t. The truth is far more ordinary than most people expect.

The deep Web refers to any part of the internet that is not indexed by standard search engines. That’s it. No special software needed, no anonymity required, no illegal activity implied. If a web page cannot be found through a Google search, it technically belongs to the deep Web.
The key characteristic that defines deep web content is simply that it sits behind some form of access restriction, a login, a paywall, a private network, or a direct URL that search engine crawlers are blocked from reaching. It’s not hidden in a dramatic sense. It’s just not public.
What Is the Dark Web?
If the deep Web is the private interior of the internet, the dark Web is the locked basement, intentionally concealed, accessible only through specific tools, and designed from the ground up for anonymity. It’s real, it’s significant, and it’s far more nuanced than headlines suggest.

The dark Web is a small, encrypted portion of the internet that exists within the deep Web but operates on an entirely different level. It cannot be accessed through a regular browser, it doesn’t appear in any search engine, and its websites use non-standard domain extensions, most commonly .onion, that only function within specialized networks.
What truly defines the dark Web isn’t just inaccessibility; it’s deliberate anonymity. Every layer of its architecture is designed to conceal the identity of both the user and the server. This makes it fundamentally different from the rest of the deep Web, where content is private but not necessarily anonymous.
How the Dark Web Is Accessed (Tor, Onion Routing Explained)
The primary gateway to the dark Web is the Tor browser, a free, open-source tool originally developed by the U.S. Naval Research Laboratory. Tor stands for The Onion Router, and its name reflects exactly how it works.
When you use Tor, your internet traffic is encrypted in multiple layers, like the layers of an onion, and routed through a series of volunteer-operated servers around the world called nodes. Each node peels back one layer of encryption and passes the data forward, but no single node ever knows both where the traffic originated and where it’s going. By the time your request reaches its destination, your identity and location are effectively untraceable.
This layered routing system is what makes the dark Web anonymous by design, and it’s the same technology that powers .onion websites, which are only resolvable within the Tor network.
Deep Web vs Dark Web vs Surface Web, Key Differences Explained
By now, the definitions are clear. But understanding what each layer is only gets you halfway there. The real clarity comes from seeing them directly compared, because the difference between the deep Web and the dark Web is not just technical; it’s fundamentally about purpose, access, and intent.
| Feature | Surface Web | Deep Web | Dark Web |
|---|---|---|---|
| Indexed by Search Engines | Yes (Google, Bing) | No | No |
| Requires Special Browser | No (Chrome, Safari) | No | Yes (Tor, I2P) |
| Requires Login/Auth | Rarely | Usually (Crucial for access) | Sometimes |
| Anonymity by Design | No | No (Linked to ID/Account) | Yes (Layered Encryption) |
| Estimated Size | ~5% of internet | ~90–95% of internet | Fraction of deep web |
| Illegal by Nature | No | No | No (Legal to browse) |
| Common Use Case | Public browsing, News | Banking, Email, Databases | Anonymous research, Whistleblowing |
Accessibility: Who Can Access Each Layer?
The surface web is open to everyone. Any device, any browser, any location, if you have an internet connection, you’re already there.
The deep Web is equally accessible to most people, just with an extra step. You need credentials, a username, a password, a subscription, or an authorized account. There’s no special software involved. Billions of people access the deep Web every day without realizing it, simply by logging in to their email or checking their bank account.
The dark Web is where accessibility becomes genuinely restricted. You need the Tor browser, or in some cases, other anonymizing networks like I2P. Even then, finding specific dark websites isn’t as simple as running a search. .onion addresses are long, complex strings that aren’t listed in conventional directories. Access is possible for anyone willing to learn how, but it requires deliberate effort.
Legality: Is the Deep Web or Dark Web Illegal?
This is one of the most important distinctions to get right, because confusion here leads to real misinformation.
The deep Web is not illegal. Full stop. There is nothing remotely unlawful about accessing your own bank account, reading a private email, or logging into a university portal. The deep Web is simply the private layer of the internet, and it is used legally by billions of people every day.
Accessing the dark Web is also not illegal in most countries. Downloading Tor and browsing .onion sites is, in itself, a legal activity in the vast majority of jurisdictions. What can be illegal is what you do once you’re there, purchasing stolen data, accessing prohibited content, or participating in criminal marketplaces. The tool isn’t the crime. The activity is.
The dark Web vs deep Web difference in legal terms comes down to this: the deep Web poses no legal risk by design, while the dark Web requires awareness of what you engage with, because the line between legal and illegal activity is much easier to cross.

Size and Scale: Which Is Bigger?
The surface web, everything Google can find, represents a surprisingly small slice of the total internet. Conservative estimates put it at around 4–5% of all online content. The deep web dwarfs it entirely, accounting for the remaining 95% or more. Every private database, every password-protected portal, every corporate intranet contributes to this vast, unseen majority.
The dark Web, by contrast, is actually quite small. Despite its enormous reputation, it represents only a fraction of the deep Web. Its perceived scale is inflated by media coverage; the reality is that it’s a niche network, significant not for its size but for the nature of what it enables.
Privacy and Anonymity Differences
Privacy and anonymity sound similar but mean very different things in this context, and the distinction between the dark and deep Web becomes clearest when you examine them through this lens.
The deep Web offers privacy through restriction. Your data is hidden not because your identity is concealed, but because access requires authentication. Your bank knows exactly who you are. Your email provider has your full account details. The privacy here is about limiting public exposure, not hiding your identity.
The dark Web offers anonymity through architecture. Tor’s onion routing means that neither the websites you visit nor any observer on the network can reliably identify who you are or where you’re connecting from. This is a fundamentally different kind of protection, one built into the technology itself rather than enforced through account controls.
In short, the deep Web keeps your data private from the public. The dark Web keeps you private from everyone.

Clear Web vs Deep Web vs Dark Web, Full Breakdown
You’ve seen the definitions. You’ve seen the comparisons. Now it’s time to bring the full picture together, because the surface web, deep Web, and dark Web aren’t three separate internets. There are three layers of the same one, each serving a distinct purpose, each connected to the others in ways that aren’t always obvious.
Surface Web Characteristics
The surface web, also called the clear Web, is the visible, publicly accessible portion of the internet that most people interact with exclusively. It’s indexed by search engines, open to the public, and designed to be found.
Its defining characteristic is discoverability. Every page on the surface web has been deliberately made available for public crawling, meaning search engine bots can visit, read, and index it. When you type a query into Google and get results, every link on that page lives on the clear Web.
The surface web is enormous in absolute terms, billions of pages, countless domains, decades of accumulated content. But relative to the full scale of the internet, it remains the smallest layer. It’s the public face of a much deeper structure, optimized for visibility rather than privacy, and built around the assumption that content is meant to be seen.
How All Three Layers Interconnect
The clear Web, deep Web, and dark Web are not isolated from each other; they exist on a continuum, and the boundaries between them are more fluid than most people realize.
A single organization can operate across all three layers simultaneously. A bank, for example, maintains a public website on the surface web where anyone can read about its services. Behind a login, its customer portals and transaction systems live on the deep Web. Its internal security team may monitor dark web forums for stolen customer credentials, an activity that bridges all three layers in a single workflow.
Similarly, the technology underpinning all three layers is shared. The same internet infrastructure, servers, cables, and protocols support all of them. The difference isn’t in the hardware. It’s in how content is structured, protected, and made accessible.
The deep Web also feeds into the dark Web structurally. The dark Web exists within the deep Web; it is, technically, a subset of the deep Web. All dark web content is deep web content by definition, because search engines index none of it. But not all deep web content is dark web content; the overwhelming majority of the deep Web is perfectly ordinary, legal, and privacy-respecting.
The surface web sits within the deep Web; it is, after all, not fully private, but it occupies its own distinct category based on indexability. The dark Web sits separately within the deep Web, distinguished not by size but by its architecture and intent.
This diagram captures something that words alone often fail to convey: the dark Web is not bigger than the surface web, and neither comes close to the scale of the deep Web. The iceberg analogy holds: what you see is the smallest part of what exists.
Key Characteristics: Deep Web vs Dark Web
For security leaders and everyday users alike, understanding the distinct properties of each internet layer is the foundation of any serious digital risk strategy. Here’s how the two compare across every dimension that matters.
| Characteristic | Deep Web | Dark Web |
|---|---|---|
| Access Method | Login credentials or direct private links. | Specialized browsers (Tor, I2P, Freenet). |
| Search Indexing | Not indexed due to access barriers (paywalls/logins). | Intentionally kept off all indexes by design. |
| Anonymity Level | Variable — depends on the specific platform. | High — anonymity is built into the architecture. |
| Primary Purpose | Protecting private info behind authentication. | Privacy, censorship resistance, anonymous communication. |
| Typical Content | Email, banking, corporate systems, subscriptions. | Forums, marketplaces, encrypted platforms. |
| Encryption | Varies by platform (e.g., HTTPS/TLS). | Extensive end-to-end encryption by default. |
| Legal Standing | Overwhelmingly legal access-controlled content. | Platform is legal; activities range from legit to criminal. |
| Hosting Structure | Conventional servers with access restrictions. | Distributed hidden services with no fixed traceable location. |
| Traceability | Varies depending on security setup. | Extremely difficult to trace by design. |
| Typical Users | Businesses, institutions, everyday internet users. | Journalists, privacy advocates, and criminals. |
Where the Deep Web and Dark Web Diverge
The differences between these two layers run deeper than access methods alone; they reflect entirely different design philosophies.
Architectural intent separates them most fundamentally. The deep Web uses standard internet infrastructure with authentication layered on top; the goal is to restrict who can see the content, not to hide that the content exists. The dark Web, by contrast, is built around specialized routing protocols whose sole purpose is to conceal the identities of both the user and the server hosting the content.
Security priorities also differ. Deep web security is about access control, ensuring that the right person accesses the right information. Dark web security is about preserving anonymity, ensuring that no observer at any point in the chain can determine who is doing what or where they are located.
Content character reflects these different purposes. The deep Web holds the legitimate, functional backbone of the modern internet, employee records, patient databases, private communications, and financial systems. The dark Web hosts a far more varied ecosystem, ranging from privacy tools and uncensored journalism to criminal marketplaces and hacking infrastructure.
Legal exposure follows the same divide. Deep web content is almost universally legal and purposely protected. The dark Web simultaneously hosts services that serve genuine human rights functions and others that exist purely to facilitate crime.
Where the Deep Web and Dark Web Overlap
Despite their differences, these two layers share more common ground than is often acknowledged.
Both are completely invisible to standard search engines; neither Google nor any conventional crawler can index their content. This shared invisibility creates a persistent challenge for organizations trying to detect unauthorized data exposure across either environment.
Both also require a degree of technical awareness to navigate properly. The deep Web is more accessible; logging into a bank account is hardly a technical feat, but understanding how it functions at a structural level still requires knowledge that most casual users simply don’t have. The dark web demands considerably more: deliberate software configuration, awareness of operational security, and an understanding of how onion routing works.
Perhaps most importantly, both serve genuine privacy functions. The deep Web protects sensitive personal and institutional information from public exposure. The dark Web provides critical anonymity infrastructure for journalists, dissidents, and whistleblowers operating in environments where exposure carries serious consequences.
Both segments are also expanding rapidly. The dark web intelligence market alone is projected to grow at a compound annual rate of over 15% through 2032, a figure that reflects how seriously the security industry has come to take monitoring what happens in these hidden layers of the internet.
For organizations building a comprehensive security posture, treating the deep Web and dark Web as a single undifferentiated threat, or dismissing them entirely, represents a significant blind spot. Each requires its own monitoring approach, risk framework, and set of responses.
Deep Web vs Dark Web: Real-World Use Cases
Understanding where these layers of the internet show up in real life makes the distinction far more concrete. Here’s how both the deep Web and dark Web serve legitimate, everyday purposes.
How the Deep Web Is Used Every Day
Most people interact with the deep Web constantly without ever labeling it as such.

Every time someone logs into their bank account, checks a social media profile, or accesses a private dashboard, that interaction occurs entirely on the deep Web, beyond the reach of search engines. Similarly, every online purchase involves entering payment details through encrypted, private channels that, by design, live outside the indexed Web.
Website developers also use the deep Web strategically. Certain pages and campaign variations are intentionally kept out of public indexes, allowing teams to serve specific homepage designs to users in specific locations, track A/B test performance, or run geo-targeted campaigns without exposing the mechanics to competitors or crawlers.
Then there’s paid content. Every paywall, whether it’s a news subscription, a premium research database, or a streaming platform, gates content that is technically on the deep Web. Search engines can’t read it. Only paying subscribers can.
How the Dark Web Is Used in the Real World
The dark Web’s legitimate use cases are more consequential than most people realize.
Journalists working on sensitive investigations, particularly those operating in or traveling through authoritarian regions, routinely rely on dark web tools to communicate with sources and file stories without exposing themselves or their contacts. The anonymity the Tor network provides isn’t a luxury in these situations. It’s a professional necessity.
That same anonymity has served political movements at critical moments in history. During the Arab Spring, when governments across the region shut down public access to social media to suppress organizing, activists turned to the dark Web to communicate, coordinate, and continue their work. For citizens living under regimes where free speech carries genuine danger, North Korea being an extreme example, the dark Web remains one of the few spaces where dissent can exist at all.
Corporate and government whistleblowers rely on it too. Platforms like SecureDrop and, notably, WikiLeaks’ own dark web presence exist specifically to give insiders a way to surface wrongdoing without sacrificing their safety or identity.
Finally, individuals facing personal threats, stalking victims, and people escaping dangerous situations sometimes use the dark Web to minimize their digital footprint and move through online spaces without being tracked. In these cases, anonymity isn’t about hiding wrongdoing. It’s about survival.
Deep Web and Dark Web Monitoring, What You Need to Know
Most people think of the dark Web as something to avoid entirely. But for security professionals, businesses, and governments, the opposite is true: the dark Web is something to watch closely. Deep and dark web monitoring has become one of the most critical components of modern cybersecurity strategy, and understanding why it matters is increasingly relevant for organizations of every size.
Why Organizations Monitor the Dark Web
The dark Web doesn’t just host threats, it telegraphs them. Long before a cyberattack becomes public, the groundwork is often laid in dark web forums, private marketplaces, and encrypted channels. Stolen credentials get listed for sale. Vulnerabilities get traded. Ransomware gets negotiated. Data breaches surface on dark web leak sites before the affected company even knows they’ve been compromised.
This is why organizations monitor the dark Web proactively, not to participate in it, but to gain early warning. When a company’s employee credentials appear on a dark web marketplace, every hour of unawareness is an hour of open exposure. Monitoring converts that blind spot into actionable intelligence.
Beyond corporate risk, governments and law enforcement agencies monitor dark web activity to track criminal networks, disrupt illegal marketplaces, and identify threats before they materialize in the real world. The dark Web is, in many ways, the most honest window into the current threat landscape, because bad actors communicate there with far less restraint than anywhere else online.
What Deep and Dark Web Monitoring Detects
Effective deep- and dark-web monitoring casts a wide net. It looks for signals across dark web forums, paste sites, encrypted marketplaces, private Telegram channels, and hidden databases, places where stolen and sensitive data tends to surface first.
The most common detections include leaked login credentials and passwords, exposed financial data such as credit card numbers or banking details, stolen personal identity information, corporate data and proprietary documents, mentions of a brand or domain in the context of planned attacks, and compromised employee accounts being sold or traded.
But monitoring doesn’t stop at the dark Web. The deep Web, with its vast ecosystem of private forums, restricted databases, and access-controlled platforms, also contains early indicators of risk. A threat actor discussing a target on a private deep web forum represents just as much of a risk signal as a dark web listing. Comprehensive monitoring covers both layers, not just the one that gets the attention.
Tools and Services Used for Dark Web Surveillance
Dark web monitoring requires specialized infrastructure. Standard security tools can’t reach .onion sites or navigate the anonymous networks where threat intelligence lives. This is where dedicated platforms become essential.
Enterprise-grade solutions crawl dark web marketplaces, monitor paste sites, and continuously scan deep web forums, indexing mentions of targeted keywords such as company names, email domains, IP addresses, and employee data. When a match surfaces, the platform triggers an alert, giving security teams the window they need to respond before damage is done.

This is exactly the problem that DeXpose.io is built to solve. DeXpose.io is a deep and dark Web monitoring platform that gives businesses real-time visibility into their exposed data across the hidden layers of the internet, before attackers can weaponize it. From leaked credentials to brand mentions in criminal forums, DeXpose.io surfaces threats that conventional security tools miss, turning dark web intelligence into a proactive line of defense rather than an afterthought.
In a threat landscape where breaches are increasingly inevitable, the question is no longer whether your data will appear on the dark Web; it’s how quickly you’ll know about it. The right monitoring solution makes all the difference.
Common Myths About the Deep Web and Dark Web
Few topics on the internet carry as much misinformation as the deep Web and dark Web. Hollywood dramatizations, sensationalist headlines, and casual misuse of terminology have built a mythology around these layers of the internet that bears little resemblance to reality. It’s time to set the record straight on the myths that refuse to die.
Myth #1: The Deep Web and Dark Web Are the Same Thing
This is by far the most widespread misconception, and it’s the one that causes the most confusion. The terms deep Web and dark Web are used interchangeably in mainstream media constantly, but they refer to fundamentally different things.
The deep Web is simply any part of the internet not indexed by search engines. It’s your email inbox, your bank account, your cloud storage, your Netflix queue. It’s enormous, entirely legal, and used by virtually everyone with an internet connection. There is nothing inherently dangerous or secretive about it.
The dark Web is a small, encrypted subset of the deep Web that requires the Tor browser to access and is specifically engineered for anonymity. It represents a fraction of the deep Web’s size and serves a very different purpose.
Calling them the same thing is like calling a bank vault the same as a locked office door; both restrict access, but they operate on completely different levels for completely different reasons. The difference between the deep Web and dark Web isn’t subtle. It’s fundamental.
Myth #2: Everything on the Dark Web Is Illegal
The dark Web’s reputation as an exclusively criminal space is one of the internet’s most stubborn myths. It persists because the illegal activity that does exist there tends to be extreme, and extreme things get covered. But the presence of illegal content doesn’t make the entire network a criminal enterprise.
The dark Web also hosts legitimate news outlets with mirror sites for censored regions, whistleblower platforms like SecureDrop, privacy-focused forums, uncensored libraries, and communication tools used by activists, journalists, and researchers operating under hostile governments. The U.S. military originally developed the Tor network itself for secure communications.
Accessing the dark Web is legal in most countries. Browsing a .onion site is no more inherently criminal than using a VPN. What matters, legally and ethically, is what you do once you’re there. The dark Web is a tool. Like most tools, its moral weight depends entirely on how it’s used.
Myth #3: You Need Special Skills to Access the Deep Web
This myth likely stems from the conflation of the deep Web with the dark Web, because while accessing the dark Web does require specific software, accessing the deep Web requires nothing more than what you already do every day.
There are no technical skills required. No special browser. No coding knowledge. No underground forums to navigate. If you’ve ever logged into an email account, checked a bank statement online, or accessed a private document through a shared link, you’ve already accessed the deep Web, completely effortlessly.
The idea that the deep Web is some technically inaccessible frontier is simply false. It’s the private, authenticated layer of the internet, and billions of people use it daily without a second thought. The mystique attached to it is a product of poor terminology, not reality.
Final Thoughts
The internet is far larger and more layered than most people ever realize. The surface web is where daily life happens. The deep Web is where private, authenticated digital infrastructure lives. The dark Web is where anonymity is engineered by design, for better and for worse.
Understanding the difference between the deep Web, dark Web, and surface Web isn’t just technical knowledge; it’s digital awareness that matters in an increasingly connected world.
But awareness alone isn’t enough. If your personal or business data finds its way onto the dark Web, knowing about it quickly is everything. That’s where DeXpose.io comes in, giving you real-time visibility into your exposed data across the hidden layers of the internet, before someone else acts on it.
The hidden internet exists whether you engage with it or not. The question is whether you’re watching it back.
Frequently Asked Questions (FAQ’s)
Is the deep Web the same as the dark Web?
No. The deep Web refers to all internet content not indexed by search engines, including your email, banking portals, and private databases. The dark Web is a small, encrypted subset of the deep Web that requires the Tor browser to access and is specifically designed for anonymity. They are related but fundamentally different.
What is the difference between the deep Web and the dark Web?
The deep Web is simply any content behind a login or access restriction, legal, ordinary, and used by billions daily. The dark Web is a deliberately hidden network within the deep Web, accessible only through Tor, and built specifically for anonymous communication. The key difference is intent: privacy vs. anonymity.
Can I accidentally access the dark Web?
No. Accessing the dark Web requires deliberately downloading the Tor browser and manually navigating to a .onion address. It cannot be stumbled upon in a regular browser, via a mistyped URL, or in a standard Google search result. It is an entirely intentional process.
Is it illegal to browse the dark Web?
In most countries, simply accessing the dark Web is completely legal. The Tor browser is a legitimate tool, and browsing .onion sites is not a crime in itself. What can be illegal is engaging with prohibited content or criminal marketplaces; once you’re there, the activity, not the access.
What is the shadow web?
The shadow web is an informal term, not a technically defined layer, sometimes used to describe the broader ecosystem of anonymous, hidden networks beyond the conventional dark Web, including networks like I2P. It has no official definition and is largely a cultural reference rather than a distinct technical reality.
How do I know if my data is on the dark Web?
The most reliable way is through a dedicated dark Web monitoring service. Platforms like DeXpose.io continuously scan dark web marketplaces, forums, and leak sites for your exposed credentials, email addresses, or sensitive data, alerting you in real time so you can act before the damage is done.