Attack surface management is the continuous practice of discovering, inventorying, and reducing every digital entry point an attacker could exploit before they have a chance to use it. It covers everything your organization exposes to the internet: domains, cloud workloads, APIs, credentials, third-party connections, and the assets your own team has forgotten exist.
The discipline has become foundational because the perimeter no longer holds a fixed shape. Cloud adoption, remote work, SaaS sprawl, and acquisitions constantly expand what you own and expose, often faster than any security team can manually track. According to ESG Research, 69% of organizations have experienced a cyberattack that started through an unknown or unmanaged internet-facing asset. The attack surface, in other words, grows whether you manage it or not.
This guide covers the full scope of attack surface management: what it is, how it differs from vulnerability management, the types of attack surfaces that matter, how External Attack Surface Management (EASM) works in practice, and the strategies security teams use to systematically reduce cyber exposure. Whether you’re building a program from scratch or pressure-testing an existing one, this is the reference you need.
What Is Attack Surface Management?
Attack surface management (ASM) is the ongoing process of discovering, classifying, and reducing every digital asset and exposure point that an external attacker could potentially reach. It treats security not as a fixed checklist but as a living program, one that adapts as infrastructure changes, new services come online, and old ones are quietly abandoned.
The discipline emerged because traditional security tools were built on a flawed assumption: that you already know what you own. ASM starts one step earlier. It asks what actually exists before asking whether it’s patched.
Attack Surface Definition in Cybersecurity
In cybersecurity, an attack surface is the complete set of points, digital, physical, or human, where an unauthorized user could attempt to enter, extract data from, or otherwise interact with a system or organization. Every open port, exposed API endpoint, public-facing login page, employee credential, misconfigured cloud storage bucket, and forgotten staging subdomain is part of it.
The defining characteristic of an attack surface is scope. It is not a list of known vulnerabilities. It is the total terrain an attacker surveys when choosing how to approach a target, including the parts the target itself has no record of.
What Is an Attack Surface? (vs. Attack Vector)
An attack surface and an attack vector are related but distinct concepts that are frequently confused. The attack surface is the what, the full collection of exposed entry points. An attack vector is the how, the specific method or pathway an attacker uses to exploit one of those points. Phishing is an attack vector. The employee inbox it lands in is part of the attack surface.
Think of it this way: the attack surface is the terrain; attack vectors are the routes through it. A large attack surface doesn’t guarantee a breach, but it increases the number of viable attack paths an attacker can take. Reducing the surface shrinks the options available to them before any vector is even attempted.
What Does ASM Actually Mean for Security Teams?
For a security team, attack surface management means owning the full answer to one deceptively simple question: what does our organization look like from the outside? That requires continuous discovery of internet-facing assets, real-time monitoring for changes, and a prioritization system that separates critical exposures from background noise.
In practice, ASM programs typically combine automated reconnaissance, DNS record scanning, certificate transparency logs, code repositories, and cloud provider footprints with human analysis to verify findings and assign remediation priority. The output is not just a list of vulnerabilities. It’s an always-current map of organizational exposure that security teams can act on, report from, and measure over time.
Gartner identified attack surface management as one of the top security and risk management trends precisely because it reframes defense around attacker perspective rather than internal assumptions, a shift that most legacy security programs were not designed to make.
Key Terminology: EASM, CAASM, and CASM Explained
As the discipline matured, analysts and vendors introduced more precise subcategories. Understanding the distinctions matters when scoping a program or evaluating solutions.
EASM (External Attack Surface Management) focuses specifically on assets reachable from the public internet. It operates entirely outside the organization’s perimeter, discovering and monitoring what an attacker with no internal access could find, enumerate, and potentially exploit. EASM is the most widely adopted form of ASM and the foundation of most commercial programs.
CAASM (Cyber Asset Attack Surface Management) takes an inside-out approach. Rather than scanning from the outside, CAASM aggregates data from internal sources, CMDBs, endpoint agents, cloud APIs, and identity systems to build a unified inventory of all assets, including those never exposed externally. It answers the question of what exists, not just what’s visible. Gartner positions CAASM as complementary to EASM rather than a replacement for it.
CASM, Continuous Attack Surface Management, is less a distinct product category and more a program posture: the commitment to running ASM as a persistent, always-on operation rather than a periodic engagement. Where a point-in-time assessment produces a snapshot, CASM produces a live feed. Most mature ASM programs operate on CASM principles whether or not they use the label.
Together, these three frameworks describe the full scope of modern attack surface management, from external visibility, to internal asset intelligence, to the operational rhythm that makes both useful.
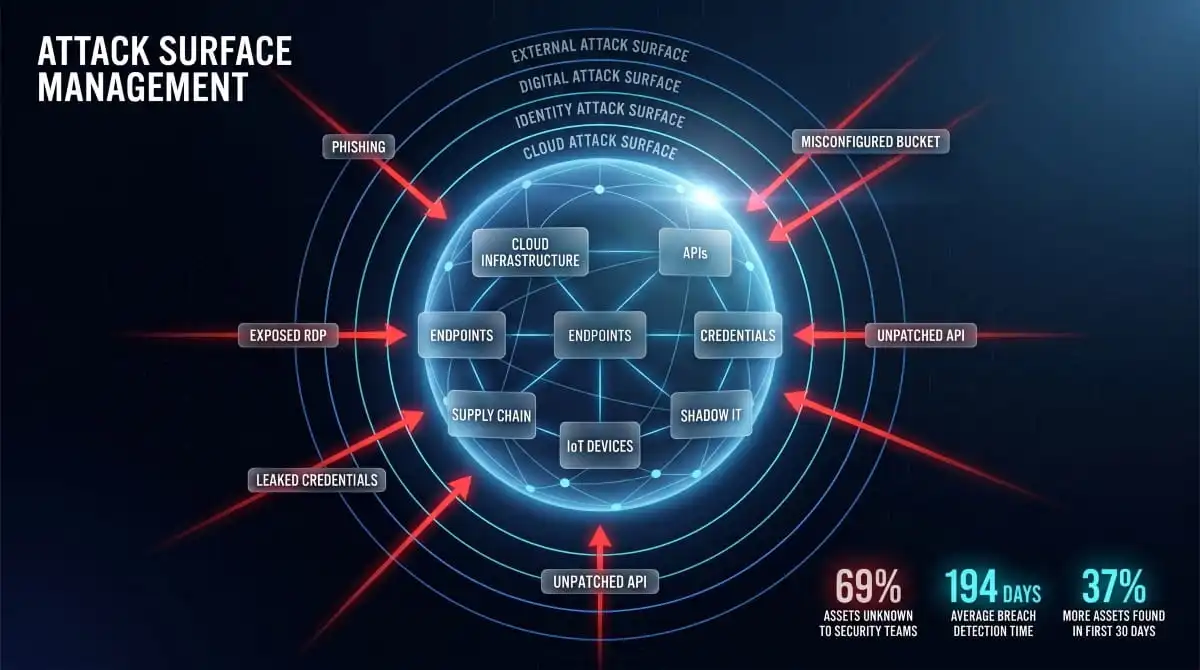
Types of Attack Surfaces: Every Entry Point You Need to Know
An organization’s attack surface is rarely a single thing. It spans multiple layers- physical, digital, human, and infrastructural- and each layer carries its own category of risk. Understanding the distinct types of attack surfaces is a prerequisite for managing them effectively, because exposure you can’t categorize is exposure you can’t prioritize.

Physical Attack Surfaces
The physical attack surface encompasses every tangible asset through which an attacker could gain unauthorized access or extract data: laptops, workstations, servers, mobile devices, USB ports, removable media, and physical access points such as server rooms and reception terminals. It is the oldest category of attack surface and, in an era of cloud-first security strategies, frequently the most underestimated.
A stolen or lost laptop with an unencrypted drive, a USB device left on a parking lot as bait, a decommissioned hard drive that was never wiped, each represents a physical exposure that no firewall addresses. Organizations with distributed workforces, shared office spaces, or field hardware are particularly exposed, because physical security controls are harder to enforce uniformly than digital ones.
Digital Attack Surfaces
The digital attack surface encompasses every software-based entry point accessible to an external party: web applications, APIs, login portals, mobile apps, administrative dashboards, development environments, and any publicly reachable service endpoint. It is typically the largest and fastest-growing category, because every new application deployment, microservice, or API integration adds to it.
Shadow IT compounds the problem significantly. When a development team spins up a staging environment or a marketing team launches a microsite without going through IT, those assets enter the digital attack surface with no security review, no monitoring, and often no ownership record. According to research by Cortex Xpanse, organizations discover an average of 35 new internet-facing services per month, a rate that most security teams cannot manually track.
Network Attack Surface
The network attack surface is defined by every point where data enters or leaves an organization’s infrastructure: exposed ports, network protocols, firewalls, VPNs, routers, DNS configurations, and any service listening on a public IP address. It includes both intentionally exposed services, such as a corporate VPN gateway, and unintentionally exposed ones, such as a database port left open after a misconfigured cloud deployment.
What makes the network attack surface particularly high-risk is that it is directly enumerable by attackers. Tools like Shodan and Censys continuously index internet-connected devices and services, meaning any exposed port or misconfigured service is potentially already known to threat actors before the organization’s own security team discovers it.
Cloud Attack Surface
The cloud attack surface has become the fastest-growing exposure category for most enterprises. It includes every resource deployed across IaaS, PaaS, and SaaS environments, cloud storage buckets, virtual machines, container workloads, serverless functions, identity and access management configurations, and the APIs that connect them, multiplied across every cloud provider in use.
Multi-cloud complexity is the core challenge. When an organization runs workloads across AWS, Azure, and Google Cloud simultaneously, each provider has its own security model, configuration syntax, and visibility tooling. A misconfiguration in one environment doesn’t automatically surface in another. Cloud assets also change constantly: containers spin up and down, new regions are activated, and SaaS integrations are added, making a static inventory of the cloud attack surface outdated almost as soon as it is produced.
Identity and Human Attack Surfaces
The identity attack surface covers every credential, account, privilege, and authentication pathway that could be exploited to gain unauthorized access: employee usernames and passwords, service accounts, API keys, OAuth tokens, SSO configurations, and privileged access credentials. When any of these are compromised, leaked, or misconfigured, they can grant an attacker access that bypasses every technical control built around the perimeter.
The human attack surface sits adjacent to it. It encompasses the people within an organization who can be manipulated, deceived, or coerced into enabling access through phishing, social engineering, pretexting, or credential reuse from unrelated personal breaches. The Verizon Data Breach Investigations Report consistently finds that the human element is involved in over 68% of breaches, making this one of the most exploited surfaces despite being the hardest to harden technically.
IoT and OT Attack Surfaces
The IoT and OT attack surface includes every connected device that isn’t a traditional endpoint: building management systems, industrial control systems (ICS), SCADA infrastructure, IP cameras, smart printers, HVAC sensors, medical devices, and any other hardware running firmware that connects to a corporate or operational network. These devices are disproportionately risky because they are designed for function, not security; they rarely receive firmware updates, often run with default credentials, and are seldom included in standard vulnerability management programs.
Operational technology (OT) environments carry a higher level of severity: a compromised ICS or SCADA system can cause physical disruption, not just data loss. The convergence of IT and OT networks, common in manufacturing, energy, and healthcare, means a breach that begins in the corporate IT environment can propagate into systems that control physical processes, with consequences well beyond data theft.
Supply Chain and Third-Party Attack Surfaces
The supply chain attack surface extends an organization’s exposure beyond its own infrastructure to include every vendor, partner, contractor, and SaaS provider with access to its systems, data, or network. A breach by a third party with privileged access is, in effect, a breach of the organization itself, regardless of how strong its internal controls are.
The SolarWinds compromise remains the defining example of supply chain attack-surface risk at scale: malicious code inserted into a trusted software update reached thousands of organizations whose environments were never directly targeted. Third-party risk is structurally difficult to manage because organizations have limited visibility into their vendors’ security posture and even less control over it. Continuous monitoring of vendor exposure, leaked credentials, detected breaches, and posture drift is the only scalable mitigation.
Attack Surface Examples: What Does This Look Like in Practice?
Abstract categories become clearer with concrete examples. A mid-sized financial services firm might find that its attack surface includes: 47 subdomains it has no active record of, three cloud storage buckets with public read permissions left over from a migration project, a VPN gateway running an unpatched version of a protocol with a known critical CVE, 200+ employee credentials circulating in dark web breach dumps from unrelated consumer data breaches, and a payroll SaaS provider that suffered a breach affecting client data six weeks prior.
None of these would appear on a standard vulnerability scan of known internal assets. All of them represent real, exploitable exposure. That gap, between what traditional security tools see and what an attacker actually sees, is precisely what attack surface management is designed to close.
Attack Surface vs. Attack Vector: Understanding the Difference
The terms attack surface and attack vector are used interchangeably in casual conversation. Still, they describe fundamentally different things, and confusing them leads to security programs that measure the wrong things. The attack surface is the totality of exposure; an attack vector is a single path through it.

How Are Attack Vectors and Attack Surfaces Related?
An attack surface is the complete landscape of potential entry points an attacker could target. An attack vector is the specific technique or pathway used to exploit one of those points. The relationship between them is one of scope: the attack surface defines the universe of possible vectors; each vector is one way to traverse it.
A corporate email system is part of the attack surface. Phishing is an attack vector that exploits it. An exposed RDP port is part of the attack surface. A brute-force credential attack is the vector. An unpatched web application is part of the attack surface. SQL injection is the vector.
This distinction matters operationally. Reducing your attack surface, removing that exposed RDP port, taking down the unpatched application, eliminates entire categories of vectors simultaneously. Defending against individual vectors without reducing the surface is a reactive posture that scales poorly against adversaries who continuously probe for new paths. Surface reduction is strategic; vector defense is tactical. Both are necessary, but only one addresses root cause.
Attack Surface vs. Vulnerability: What’s the Distinction?
An attack surface and a vulnerability are related concepts at different levels of specificity. The attack surface is the full set of exposure points that could theoretically be targeted. A vulnerability is a confirmed weakness within one of those points that makes exploitation practically viable.
An asset can be part of the attack surface without containing a known vulnerability; it is exposed and reachable, but not currently documented as exploitable. Conversely, a vulnerability only represents meaningful risk if it exists on an asset within the reachable attack surface. An unpatched system on an air-gapped network carries a different risk profile than the same unpatched system exposed to the public internet.
This distinction shapes how security programs should be structured. Attack surface management concerns the entire attack surface, including known, unknown, and forgotten assets. Vulnerability management operates on the subset of that terrain where specific weaknesses have been identified. A robust program needs both: ASM to ensure comprehensive visibility, and vulnerability management to prioritize remediation within that inventory. Running vulnerability management without ASM means scanning what you know about while remaining blind to everything else.
Threat Surface vs. Attack Surface vs. Protect Surface
These three terms frame the same security landscape from three different perspectives, and each one is useful for a different planning purpose.
The attack surface is the set of all points where an attacker could attempt to gain access, the full exposure map as seen from outside the organization. The threat surface is a broader concept that encompasses not only where an attacker could reach, but also the full range of threats, including insider threats, environmental risks, and non-technical vectors like social engineering that could cause harm. Every attack surface is part of the threat surface, but the threat surface extends beyond technical attack surfaces into human, procedural, and contextual risks.
The protect surface, a concept popularized by John Kindervag as part of the Zero Trust framework, inverts the framing entirely. Rather than trying to identify and defend everything that could be attacked, the protect surface asks: what are the most critical assets, data, services, and functions (DAAS) that must be protected above all else? The protect surface is intentionally small and precisely defined, the crown jewels. Zero Trust architecture is then built outward from it.
Used together, these three concepts give security leaders a complete mental model: the attack surface tells you where you’re exposed, the threat surface tells you what could go wrong, and the protect surface tells you what you cannot afford to lose.
Attack Surface vs. Attack Tree: A Modeling Perspective
An attack surface and an attack tree both serve as analytical tools for understanding organizational risk, but they operate at different levels of abstraction and serve different analytical purposes.
The attack surface is an inventory, a map of all the points through which an attacker could engage with a system. It is broad by design, capturing the full scope of exposure without necessarily specifying how any individual point would be exploited. Attack surface management as a discipline is built around continuously maintaining and reducing this map.
An attack tree is a structured threat modeling technique that starts from a specific goal, “exfiltrate customer database,” “achieve ransomware deployment,” “gain domain admin access”, and works backward through every sequence of steps an attacker could take to achieve it. Each branch of the tree represents an alternative path to the same objective, with sub-branches detailing the conditions required at each step.
The two tools are complementary rather than competitive. The attack surface tells you what exists and where you’re exposed. An attack tree shows how a specific threat actor might chain exposures to mount a successful attack. Security teams doing serious threat modeling use attack surface data as the raw material that populates the leaves of their attack trees, the actual assets, credentials, and services that each branch of the model ultimately depends on.
Attack Surface Analysis: How to Identify and Measure Your Exposure
Attack surface analysis is the structured process of identifying, cataloguing, and evaluating every point in a system or organization where an attacker could attempt to gain unauthorized access. It is how security teams move from a vague awareness of exposure to a precise, actionable picture of what exists, what’s reachable, and what carries the most risk.

What Is Attack Surface Analysis?
Attack surface analysis is the practice of systematically examining an organization’s or application’s exposure to determine the full scope of potential attack entry points. It answers three questions in sequence: what assets and interfaces exist, which of them are reachable by an external or unauthorized party, and which of those reachable points represent the highest concentration of risk.
The analysis is not a one-time audit. Because infrastructure changes continuously, new services are deployed, old ones are decommissioned, cloud configurations drift, and credentials are rotated or forgotten. Attack surface analysis is most effective when treated as a recurring or continuous process rather than a periodic exercise. A snapshot taken six months ago describes a surface that no longer exists.
Attack Surface Discovery: Finding Unknown Assets
Discovery is the foundational phase of attack surface analysis and the one most likely to yield surprises. The goal is to build a complete inventory of all assets that could be reached by an attacker, including those the organization does not have on record.
Unknown assets are not rare edge cases. They accumulate systematically through shadow IT, where teams deploy services outside formal IT processes; through cloud sprawl, where infrastructure is provisioned and abandoned faster than inventories are updated; through mergers and acquisitions, where inherited infrastructure is often poorly documented; and through simple operational drift, where staging environments, development subdomains, and test APIs outlive their intended lifespan.
Discovery techniques draw on the same sources an attacker would use: certificate transparency logs, which record every TLS certificate issued for a domain; passive DNS, which tracks historical resolution records; WHOIS and ASN lookups, which map IP block ownership; code repository scanning, which surfaces credentials and internal hostnames accidentally committed to public repositories; and search engine dorking, which can expose misconfigured services indexed by Google or Bing. The output of discovery is a raw asset inventory, the foundation everything else is built on.
Attack Surface Mapping: Visualizing Your Full Exposure
Once assets are discovered, attack surface mapping organizes them into a coherent picture of organizational exposure. Where discovery produces a list, mapping produces a graph showing relationships among assets, ownership attribution, environment classification, and connections between domains, IP ranges, certificates, and services.
Effective attack surface mapping goes beyond asset enumeration to capture context. Which assets are production-facing versus development? Which belong to subsidiaries or third parties? Which changed in the last 24 hours? Which share certificate infrastructure, suggesting a common origin or owner? This relational layer transforms raw inventory into an actionable exposure map that security teams can use to identify risk clusters, track changes over time, and communicate exposure clearly to stakeholders who need to prioritize remediation resources.
Attack Surface Scoring and Metrics
Measuring an attack surface requires moving from qualitative description to quantitative assessment. Several frameworks and methodologies provide structure for doing this.
NIST’s guidelines on attack surface measurement focus on the Relative Attack Surface Quotient (RASQ), a comparative measure that evaluates an application’s attack surface based on the number of methods, data inputs, data outputs, and channels available to unauthorized users. The principle is straightforward: an application with fewer exposed interfaces and data paths has a smaller, more defensible attack surface than one with many.
The OWASP Attack Surface Analysis Cheat Sheet approaches the same problem at the application level, recommending that teams catalogue all entry points (every URL, form field, API endpoint, and authentication pathway) and all trust boundaries (every point where data crosses between systems with different privilege levels). OWASP’s guidance emphasizes that attack surface analysis should be integrated into code review and architecture review processes, not treated as a post-deployment concern.
For enterprise-level programs, attack surface scoring typically incorporates asset criticality, exposure severity, exploitability signals such as CISA’s Known Exploited Vulnerabilities catalog, and business context, weighting findings by the revenue, regulatory, or operational significance of the affected asset. This composite scoring allows large security teams to work from a prioritized queue rather than treating every finding with equal urgency.
Attack Surface Analysis in the SDLC
Integrating attack surface analysis into the software development lifecycle (SDLC) is one of the highest-leverage practices a security team can adopt, because it addresses exposure at the point of creation rather than after the fact. The principle is shift-left security: identifying and reducing attack surface during design and development, when changes are cheap, rather than post-deployment, when they are expensive and disruptive.
In practice, SDLC integration means reviewing the attack surface implications of architectural decisions during design, asking how many new entry points a proposed feature creates and whether they are necessary. It means including attack surface analysis in code reviews, checking whether new endpoints require authentication, whether input validation is properly scoped, and whether error handling exposes internal system information. It means tracking the delta between versions, documenting how each release changes the attack surface, not just what features it adds.
OWASP recommends maintaining an explicit attack surface document alongside the codebase that is updated with each significant release. Teams that follow this practice accumulate a longitudinal record of exposure changes, enabling both security reviews and incident investigations to proceed significantly faster.
Attack Surface Analysis vs. Threat Modeling: Key Differences
Attack surface analysis and threat modeling are complementary disciplines that are frequently conflated, but they answer different questions and operate at different levels of specificity.
Attack surface analysis is descriptive and inventory-focused. It asks: what exists, what’s exposed, and where are the entry points? The output is a terrain map, comprehensive but not yet tied to specific adversary behavior or attack scenarios.
Threat modeling is analytical and scenario-focused. It asks: given this terrain, what could an attacker do, in what sequence, with what probability and impact? Frameworks like STRIDE, PASTA, and LINDDUN take the entry points identified in attack surface analysis and reason through how they could be chained together into realistic attack paths. The output is a set of prioritized threat scenarios, each tied to specific mitigations.
The practical relationship between them is sequential: attack surface analysis produces the inventory that threat modeling uses as raw material. Running threat modeling without a current attack surface analysis means modeling against an incomplete picture of what’s actually exposed. Running attack surface analysis without threat modeling means you have a map but no theory about where the most dangerous routes run through it.
The First Step in Analyzing Your Attack Surface
The first step in analyzing your attack surface is defining the scope of what you’re examining, then immediately testing whether it’s complete. This means starting with what your organization believes it owns: the known domains, IP ranges, applications, and cloud accounts on record. Then, before any analysis begins, run external discovery against that seed data to surface everything that exists but isn’t on the list.
This sequencing matters because analysis built on an incomplete inventory produces a false sense of coverage. Organizations that skip the discovery phase and move straight to vulnerability assessment of known assets are, by definition, analyzing a subset of their actual attack surface. The assets they don’t know about- the forgotten subdomain, the misconfigured cloud bucket, the shadow IT deployment- are often precisely the ones an attacker will find first, because they are the least likely to have any defensive controls applied to them.
Start with what you know. Expand immediately to what you don’t. The gap between those two inventories is where the most significant unmanaged risk typically lives.
External Attack Surface Management (EASM): What It Is and Why It Matters
External attack surface management is the discipline of continuously discovering, monitoring, and reducing every internet-facing asset and exposure point that an attacker could reach without any internal access. It is the operationalization of the attacker perspective, systematic, continuous, and scoped entirely to what’s visible from outside the organization’s perimeter.

What Is External Attack Surface Management?
External attack surface management (EASM) is a security practice and technology category focused on identifying and managing assets, services, and exposures reachable from the public internet. Unlike traditional security tools that operate from within a known network boundary, EASM works from the outside in, discovering what an organization exposes to the world before evaluating whether those exposures are secure.
The “external” qualifier is significant. EASM does not rely on agents, internal network access, or pre-existing asset inventories. It begins with a seed, typically a domain name or company identifier, and uses passive reconnaissance techniques to build a complete picture of the organization’s internet-facing footprint. The result captures not just what the security team knows about, but what actually exists: the forgotten subdomain, the misconfigured API, the acquired subsidiary running on unpatched legacy infrastructure, the development environment that was never taken offline.
Gartner formalized EASM as a distinct market category in 2021, recognizing that managing external exposure requires a fundamentally different approach from vulnerability management or traditional perimeter defense. The category has grown rapidly since, driven by the reality that the external attack surface is expanding faster than most organizations can manually track.
How EASM Works: Discovery → Inventory → Monitoring → Remediation
EASM operates as a continuous cycle rather than a linear process, but understanding it sequentially clarifies what each phase contributes.
Discovery is where EASM begins. Automated reconnaissance scans across certificate transparency logs, passive DNS records, WHOIS and ASN data, code repositories, internet indexing services, and dark web sources to identify every asset that resolves to or is attributable to the target organization. This phase surfaces assets the organization has on record and, critically, those it doesn’t.
Inventory takes the raw output of discovery and transforms it into a structured, deduplicated asset graph. Each asset is assigned to a domain, business unit, geography, or environment, and is tagged with metadata including open ports, running services, TLS certificate health, technology fingerprints, and ownership classification. The inventory is not a static export; it is a living record that updates continuously as the discovery layer feeds new data into it.
Monitoring watches the inventory for change. New assets appearing, services being added, certificates expiring, configurations drifting, credentials surfacing in breach data– each represents a signal that the exposure profile has shifted. Effective EASM platforms surface these signals with enough context that security teams can triage them quickly, distinguishing a new legitimate deployment from an unauthorized exposure or a shadow IT asset that needs review.
Remediation closes the loop by translating findings into action. This means routing confirmed exposures to the right owner, through integrations with Jira, ServiceNow, or Slack, with enough context to act without requiring a separate investigation. For critical findings, this may mean initiating takedown processes, revoking credentials, or escalating to an incident response workflow. The remediation phase is where EASM converts visibility into measurable risk reduction.
External Attack Surface Scanning and Discovery
External attack surface scanning is the technical mechanism through which EASM programs build and maintain their asset inventory. It operates passively, without sending probes that could disrupt services or trigger security alerts, by harvesting data from continuously updated public sources within the internet’s infrastructure.
Certificate transparency logs are among the most valuable sources. Every TLS certificate issued by a public certificate authority is logged in a publicly accessible ledger, and those certificates contain domain names and subdomains that reveal the full scope of an organization’s web presence, including services provisioned without IT’s knowledge. Passive DNS databases capture historical resolution records, surfacing domains that may have been active in the past and could still be attributed to the organization. ASN and IP block data maps which IP ranges an organization controls and what services are running on them.
Code repositories add a further dimension. Public GitHub, GitLab, and Bitbucket repositories frequently contain hardcoded credentials, internal hostnames, API keys, and infrastructure references that developers accidentally commit. A single leaked credential in a public repository can expose access to internal systems that no external scan would otherwise reach. Comprehensive external attack surface scanning treats repository exposure as a first-class signal, not an afterthought.
Continuous External Attack Surface Monitoring
The Word “continuous” in external attack surface monitoring is not marketing language; it describes a fundamental architectural requirement. An attack surface is not a fixed object. It changes every time a developer pushes a new service, a cloud configuration is modified, a certificate expires, or a credential appears in a breach dump. A monitoring system that checks weekly or monthly is not measuring a moving target; it is producing periodic snapshots of something that has already changed.
Continuous external attack surface monitoring means the detection pipeline runs around the clock, with signal latency measured in minutes rather than days. When a new subdomain is registered that matches a target organization’s naming convention, it surfaces immediately. When a TLS certificate for a production domain is issued from an unexpected certificate authority, a potential sign of a fraudulent certificate or infrastructure compromise, it triggers an alert before it can be weaponized. When an employee’s credentials appear in a freshly published breach corpus, the exposure is flagged the same day rather than discovered weeks later during a scheduled review.
According to IBM’s Cost of a Data Breach Report, the average time to identify a breach is 194 days. Continuous monitoring directly attacks that number by compressing the window between exposure and detection, which attackers depend on.
EASM Best Practices for Enterprise Security Teams
Building an effective external attack surface management program at enterprise scale requires more than deploying a tool. The practices that separate mature programs from immature ones are largely operational.
Start with comprehensive seed data. EASM is only as complete as the organizational identifiers it receives. Most programs begin with primary domains but miss subsidiaries, acquired companies, legacy brand domains, and cloud provider accounts. Investing time upfront in a complete seed inventory, covering every legal entity, domain registrar account, and cloud organization, produces dramatically better discovery coverage.
Establish clear asset ownership before alerts begin flowing. The most common reason EASM findings go unresolved is not a lack of visibility but a lack of accountability: no one knows who owns the exposed asset, so no one acts on the finding. Mapping assets to business units, application owners, and engineering teams before the monitoring program goes live ensures that when a critical exposure surfaces, it is routed to the person who can fix it.
Integrate with existing workflows rather than creating parallel ones. Security teams already working in Jira, ServiceNow, or Slack will not adopt a separate EASM portal as their primary workflow tool. EASM programs that route findings directly into existing ticketing and communication systems achieve faster remediation times and higher program adoption than those that require analysts to context-switch between platforms.
Finally, measure reduction, not just discovery. The operational metric that matters is not how many assets were found; it is how many exposures were closed, how quickly, and whether the total exposure profile is trending in the right direction over time. Programs that track and report on surface reduction give security leadership a defensible narrative for program investment.
External vs. Internal Attack Surface Management
External and internal attack surface management are complementary disciplines that address different segments of the same overall exposure problem, and understanding where one ends and the other begins clarifies how to structure a complete program.
External attack surface management operates from outside the perimeter. It discovers and monitors assets that are reachable without any internal access, everything visible to the public internet, from a customer-facing web application to a misconfigured cloud storage bucket. EASM requires no agents, no internal network visibility, and no pre-existing asset inventory. Its strength is in finding what the organization doesn’t know it’s exposing.
Internal attack surface management, often implemented through Cyber Asset Attack Surface Management (CAASM) platforms, operates within the perimeter. It aggregates data from internal sources, such as endpoint detection tools, CMDBs, cloud provider APIs, identity systems, and network scanners, to build a comprehensive inventory of all assets, including those with no external exposure. Its strength is in mapping the internal attack surface: east-west movement paths, misconfigured internal services, unmanaged endpoints, and overprivileged accounts that an attacker with internal access could exploit.
The gap between them is where the most serious breaches occur. An attacker who gains initial access through an external exposure, a phished credential, or an unpatched public-facing service then moves laterally through the internal attack surface toward high-value targets. A security program that manages only the external surface knows how the attacker got in but not where they went. One that manages only the internal surface is blind to how the attacker arrived. Mature organizations build toward both, using EASM for external visibility and CAASM for internal completeness, aiming to leave no segment of the full attack surface unmonitored.
Cloud Attack Surface Management: Securing Dynamic, Distributed Environments
Cloud attack surface management is the practice of continuously discovering, monitoring, and reducing the exposure introduced by cloud infrastructure across every provider, account, region, and service an organization operates. It is one of the fastest-growing and most complex segments of the broader attack surface management discipline, because the environment it governs never stops changing.

Why Cloud Environments Expand Your Attack Surface
Cloud adoption expands the attack surface in ways that have no direct equivalent in traditional on-premises infrastructure, and the expansion happens by design. Every new cloud account, region activation, storage bucket, serverless function, container workload, and SaaS integration adds a new surface that must be inventoried, configured securely, and continuously monitored. The agility that makes cloud infrastructure valuable, the ability to spin up new resources in seconds, is precisely what makes it difficult to secure.
Several structural characteristics of cloud environments drive this expansion. Provisioning is decentralized: developers, data teams, and marketing functions can deploy cloud resources without going through IT or security review, creating shadow cloud infrastructure that accumulates outside any formal inventory. Resources are ephemeral: containers, serverless functions, and spot instances may exist for minutes or hours before being terminated, making point-in-time scanning an unreliable approach to discovery. And configurations drift constantly: a storage bucket that was correctly configured at deployment can become publicly accessible following a routine permission change made to solve an immediate operational problem.
The scale of this challenge is reflected in breach statistics. Tenable’s research found that 74% of organizations have cloud exposures that put them at significant risk, with misconfiguration consistently ranking as the leading cause of cloud security incidents, above malware and exploited vulnerabilities combined.
Cloud Attack Surface Discovery and Mapping
Discovering the cloud attack surface requires a fundamentally different approach from traditional asset discovery. On-premises infrastructure is relatively static and bounded; cloud infrastructure is dynamic, multi-account, and spread across provider regions that can be activated unilaterally by any team with provisioning access.
Effective cloud attack surface discovery operates across two dimensions simultaneously. The first is internal: querying the cloud provider’s APIs directly to enumerate every resource across every account and region, including EC2 instances, S3 buckets, RDS databases, Lambda functions, API Gateway endpoints, IAM roles, and every other resource type the provider exposes. This approach requires appropriate access credentials but produces a comprehensive, authoritative inventory of what has been provisioned.
The second dimension is external: treating the cloud environment as an external attacker would, scanning public-facing IP addresses, subdomains resolving to cloud infrastructure, publicly accessible storage buckets, and exposed service endpoints without using internal credentials. This external perspective is essential because it captures misconfigured resources that are unintentionally public-facing, the resources that internal API queries would list as existing but not necessarily flag as externally reachable.
Cloud attack surface mapping then connects these two inventories into a unified asset graph, showing which internal resources have external exposure, how they relate to each other, which accounts and teams own them, and how their configuration has changed over time. The relational layer, recognizing that a public S3 bucket contains data also accessible by a Lambda function triggered by an API Gateway endpoint, elevates mapping from a simple inventory to a genuine exposure picture.
Multi-Cloud Attack Surface Management Challenges
Multi-cloud environments amplify the challenges that individual cloud deployments already pose, and introduce several new ones with no single-provider equivalent. Organizations running workloads across AWS, Azure, Google Cloud, and a collection of SaaS platforms are not managing a single cloud attack surface; they are managing several, each governed by different security models, configuration syntax, identity systems, and native tooling that does not communicate with the others by default.
The visibility problem is the most immediate. AWS Security Hub, Microsoft Defender for Cloud, and Google Security Command Center each provide excellent native visibility within its respective environment. Still, none of them surface exposure across all three simultaneously. A security team relying on native tooling in a multi-cloud environment is working across three separate dashboards that describe three distinct attack surfaces, with no unified view of the total organizational exposure.
Consistency is the second challenge. The same security intent, ensuring that no storage bucket is publicly accessible without explicit justification, must be implemented differently in each cloud environment, using different policy frameworks, different configuration parameters, and different enforcement mechanisms. A misconfiguration in one environment is not automatically detected by the controls configured for another environment. Multi-cloud attack surface management requires a layer of abstraction above individual provider tooling that normalizes findings, enforces consistent policy, and presents a single, coherent exposure map regardless of where the underlying resources are hosted.
Identity is the third challenge and frequently the most dangerous. Multi-cloud environments proliferate service accounts, API keys, cross-cloud trust relationships, and federated identity configurations, creating complex, difficult-to-audit privilege chains. An overprivileged service account in one cloud environment can, through a trust relationship, become a lateral movement path into another, a risk that no single provider’s native identity tooling is designed to detect.
EASM for AWS, Azure, and Hybrid Cloud Environments
External attack surface management applied to cloud environments focuses specifically on what is reachable from the public internet, the subset of cloud infrastructure that an attacker without internal access could discover and attempt to exploit. In AWS, Azure, and hybrid environments, this includes a distinct set of exposure patterns that recur consistently across organizations of every size.
In AWS environments, the most common external exposures involve S3 buckets with misconfigured public access policies, EC2 instances with security group rules permitting inbound access from any IP address (0.0.0.0/0) on sensitive ports, API Gateway endpoints deployed without authentication requirements, and CloudFront distributions serving content from origins with overly permissive CORS policies. AWS’s scale amplifies the risk: with hundreds of services and thousands of configuration parameters, the surface area for misconfiguration is enormous.
In Azure environments, external exposure commonly surfaces through Azure Blob Storage containers with anonymous read access, Azure App Service deployments with debugging endpoints left enabled, exposed Azure SQL instances with overly permissive firewall rules, and Azure Active Directory misconfigurations that allow external identity federation beyond intended boundaries. Microsoft Defender External Attack Surface Management (Defender EASM) provides native tooling for this visibility, though organizations with multi-cloud or hybrid environments typically require a provider-agnostic layer above it.
Hybrid environments, combining on-premises infrastructure with one or more cloud providers, introduce additional complexity through the connections between them. VPN gateways, Direct Connect links, and hybrid identity configurations create pathways that can be discovered and potentially exploited from either direction. EASM for hybrid environments must treat the connection layer itself as part of the attack surface, not just the endpoints on either side.
Cloud Attack Surface Reduction Strategies
Reducing the cloud attack surface is a continuous operational discipline rather than a one-time hardening exercise, because the surface regenerates through normal infrastructure activity faster than most teams can manually remediate it. Effective reduction strategies address the structural causes of cloud exposure rather than chasing individual findings.
The most impactful structural control is enforcing least-privilege access across all cloud accounts and service identities. Overprivileged IAM roles, service accounts with administrative permissions, and long-lived API keys that are never rotated each represent persistent exposure that sits below the threshold of most alert systems. Implementing just-in-time access, rotating credentials systematically, and auditing permission grants against actual usage patterns reduces the volume of identity-layer exposure before it can be exploited.
Policy-as-code is the second high-leverage strategy. Encoding security requirements- no public bucket access, no inbound 0.0.0.0/0 on sensitive ports, no unencrypted data at rest- as machine-enforceable policies applied at provisioning time prevents misconfiguration from entering the environment in the first place. Tools like AWS Service Control Policies, Azure Policy, and infrastructure-as-code scanning frameworks shift enforcement left, just as attack surface analysis in the SDLC shifts security review left in application development.
Continuous misconfiguration monitoring closes the gap that policy-as-code cannot fully prevent. Any authorized user can change configurations that were correct at deployment at any time. Monitoring for drift, comparing current configuration state against a defined baseline and alerting immediately when deviations occur, ensures that the window between a misconfiguration being introduced and being detected is measured in minutes rather than months.
Cloud-Native Attack Surfaces and Compliance Implications
Cloud-native architectures, built on containers, microservices, serverless functions, and managed Kubernetes, introduce attack surface patterns that have no direct equivalent in traditional application architectures, and their compliance implications are still being worked out across most major regulatory frameworks.
Container environments expose attack surface through image registries, orchestration APIs, and the runtime itself. A container image with a vulnerable base layer, pulled into production dozens of times a day, represents an attack surface that scales with deployment velocity. Kubernetes API servers exposed without proper authentication, or with overly permissive role bindings, represent a single control-plane vulnerability with a blast radius across every workload the cluster runs.
Serverless architectures compress the attack surface in some dimensions; there is no server to patch, no operating system to harden, while expanding it in others. Every event source that can trigger a Lambda function or Azure Function is an entry point. Every permission granted to that function is part of the identity attack surface. The ephemeral, event-driven nature of serverless execution makes traditional monitoring approaches unreliable and requires purpose-built observability.
From a compliance perspective, cloud-native attack surfaces create audit challenges that legacy frameworks were not designed to address. CMMC, PCI DSS, ISO 27001, and SOC 2 all require organizations to maintain an accurate inventory of assets in scope for the applicable controls, a requirement that is structurally difficult to meet in environments where assets are ephemeral, autoscaling, and spread across multiple provider regions. Organizations pursuing certification in cloud-native environments are increasingly required to demonstrate continuous inventory and monitoring capabilities, not just point-in-time compliance evidence, as auditors become more sophisticated about what cloud environments actually look like in production.
Cyber Asset Attack Surface Management (CAASM): Full Asset Visibility
Cyber asset attack surface management (CAASM) is the practice of aggregating data from internal security and IT sources to build a unified, continuously updated inventory of every asset an organization owns and to understand the attack-surface implications of each. Where external attack surface management looks outward from the internet, CAASM looks inward from within the organization, filling visibility gaps that external scanning alone cannot reach.

What Is CAASM?
CAASM is a security discipline and technology category focused on solving the asset visibility problem from the inside out. It works by integrating with the tools and data sources an organization already operates- endpoint detection and response platforms, cloud provider APIs, CMDBs, identity systems, vulnerability scanners, network management tools, and SaaS application directories- and consolidating their output into a single, normalized asset inventory.
The core insight behind CAASM is that most organizations already have asset data scattered across multiple systems. The problem is not that the data doesn’t exist; it’s that it lives in silos, uses inconsistent identifiers, and cannot be queried holistically. A laptop might appear in the endpoint agent console under a hostname, in the CMDB under a serial number, in the identity system under an assigned user, and in the vulnerability scanner under an IP address, with no automatic linkage between the four records. CAASM platforms ingest all of these sources, resolve the identities, and produce a single authoritative record for each asset that security teams can query, monitor, and act on.
Gartner introduced CAASM as a formal market category in its 2021 Hype Cycle for Security Operations, defining it as technology that enables security teams to solve asset visibility and coverage challenges through API-based integrations with existing tools. The analyst firm positioned it as a foundational capability for organizations seeking to understand their combined internal and external attack surface.
CAASM vs. EASM: How They Differ and Overlap
CAASM and EASM address the same fundamental problem, incomplete visibility into organizational exposure, but they approach it from opposite directions, using different data sources and producing different types of insight.
EASM operates externally. It requires no internal access, no agent deployment, and no integration with internal systems. It discovers what’s externally reachable by simulating attacker reconnaissance, scanning public sources, certificate logs, DNS records, and breach data to surface the organization’s internet-facing footprint. Its strength lies in identifying assets the organization doesn’t know are exposed. Its limitation is that it sees only what an external attacker can see: it has no visibility into internal network topology, unmanaged endpoints with no external exposure, or the internal relationships between assets.
CAASM operates internally. It requires integrations with existing tools and data sources, and its quality is directly proportional to the completeness and accuracy of those sources. Its strength is comprehensive internal asset intelligence: every endpoint, every cloud resource, every user account, every software installation, correlated into a unified view that no single internal tool provides on its own. Its limitation is that it depends on the organization already having tooling that covers the assets it needs to inventory. Assets that fall outside any existing tool’s coverage- a forgotten server that was never enrolled in endpoint management, a cloud account provisioned outside the standard process- may not appear in CAASM unless supplemented by external discovery.
The overlap between them is where the most complete picture emerges. An asset identified by EASM as externally reachable can be cross-referenced with the CAASM inventory to determine whether it is a known, managed asset or an unknown, unmanaged asset. An unmanaged asset in the CAASM inventory can be checked against EASM data to determine whether it has external exposure. Organizations that operate both capabilities in an integrated way achieve what neither provides alone: full-spectrum visibility across the entire attack surface, internal and external, known and unknown.
CAASM Use Cases: Shadow IT, Unmanaged Assets, Hybrid Environments
The operational value of CAASM is most visible in the specific problems it solves that other security tools consistently fail to address.
Shadow IT is the canonical CAASM use case. When employees or teams deploy applications, cloud resources, or devices outside the formal IT procurement and provisioning process, those assets accumulate in a blind spot, not enrolled in endpoint management, not scanned by the vulnerability program, not covered by security policy. CAASM surfaces shadow IT by identifying assets that appear in some data sources but not others: a device that shows up in network logs but is absent from the endpoint management console, a cloud account that appears in expense reports but not in the cloud security platform. These discrepancies are the fingerprints of unmanaged exposure.
Unmanaged and unagented assets represent a related challenge. Printers, IoT devices, OT systems, BYOD endpoints, and contractor machines often lack the agent-based monitoring that endpoint security programs depend on. CAASM platforms that integrate with network discovery tools, DHCP logs, and identity systems can surface these assets even without agent coverage, ensuring they are represented in the overall inventory and flagged for appropriate risk assessment.
Hybrid environments are where CAASM delivers some of its most significant operational value. Organizations running a combination of on-premises infrastructure, multiple cloud providers, and a growing SaaS footprint have no single native tool that spans all three. Each environment has its own inventory system, identity model, and security tooling. CAASM sits above all of them as a normalization and correlation layer, translating heterogeneous asset data into a unified model that security teams can work from regardless of where the underlying asset lives.
Key Features of a CAASM Platform
Not all asset management platforms deliver genuine CAASM capability. The features that define a mature platform and distinguish it from a simple CMDB or asset inventory tool reflect the discipline’s core requirements.
API-based integration breadth is the foundational requirement. A CAASM platform is only as useful as its ability to ingest data from the tools the organization already runs. The depth of its integration library, covering endpoint detection platforms, cloud providers, identity systems, vulnerability scanners, network management tools, ticketing systems, and SaaS directories, determines how complete the resulting inventory will be. Platforms that require manual data imports or support only a narrow set of integrations cannot produce the unified view that CAASM promises.
Asset correlation and identity resolution are what separate CAASM from simple data aggregation. The platform must recognize that the hostname in the endpoint console, the IP address in the network scanner, the serial number in the CMDB, and the user assignment in the identity system all refer to the same physical or virtual asset, and merge them into a single, deduplicated record. Without this capability, the platform produces a larger version of the same fragmented data problem it was meant to solve.
Coverage gap detection is the operational output that justifies CAASM investment. By comparing the asset inventory against the coverage scope of each security tool- which assets have endpoint agents, which are being scanned by the vulnerability program, and which are enrolled in patch management- the platform surfaces the assets that are visible in some systems but unprotected by others. These gaps are the highest-priority findings a CAASM program produces, because they represent known assets with confirmed security blind spots.
Continuous synchronization ensures the inventory reflects the current state of the environment rather than a snapshot. Assets change status, move between environments, go offline, and are constantly provisioned and decommissioned. A CAASM platform that updates its inventory in near real time, rather than through scheduled batch imports, gives security teams a reliable foundation for decision-making rather than a document that is accurate only on the day it was generated.
How to Reduce Your Attack Surface: Proven Strategies and Best Practices
Reducing your attack surface means systematically eliminating the entry points, permissions, and exposures that an attacker could use, before they find them. It is the most structurally sound form of security investment because it removes risk rather than detecting or responding to it after the fact.

The Principle of Minimizing Attack Surface
Minimizing attack surface is one of the oldest and most durable principles in security engineering, formalized in the academic literature decades before cloud infrastructure made it an operational imperative. The principle states that a system should expose only the minimum set of interfaces, services, data paths, and privileges necessary for its intended function, and that every exposure beyond that minimum represents unnecessary risk.
The practical implication is straightforward: every open port that isn’t required, every service that could be disabled, every permission that exceeds what a user or process actually needs, and every publicly accessible endpoint that serves no legitimate external purpose is an attack surface that exists purely as a liability. It provides no benefit to the organization and gives the attacker options.
What makes the principle genuinely powerful is its multiplicative effect. Eliminating a single unnecessary service doesn’t just remove one vulnerability; it removes every current and future vulnerability in that service, every attack vector that targets it, and every lateral movement path that depends on it. Surface reduction compounds in a way that patching individual vulnerabilities does not.
Attack Surface Reduction Best Practices by Asset Type
Attack surface reduction looks different depending on the asset category being hardened, because exposure patterns and available controls vary significantly across infrastructure types.
For web applications and APIs, reduction means turning off unused endpoints, enforcing authentication on every externally reachable interface, removing debug modes and verbose error messages from production environments, and retiring legacy application versions rather than running them in parallel with current ones. Every undocumented API endpoint that remains active in production is an entry point that receives no security review and generates no monitoring alerts.
For endpoints and workstations, reduction means uninstalling software that is not needed for the device’s function, disabling services like remote desktop, SMB, and Bluetooth when they are not operationally required, enforcing application allowlisting to prevent unauthorized execution, and ensuring that local administrator rights are removed from standard user accounts. The attack surface of an endpoint is defined almost entirely by what is installed and enabled on it.
For cloud infrastructure, reduction means enforcing resource tagging and ownership policies so that unowned assets are automatically flagged, deleting or archiving resources that are no longer active rather than leaving them in an idle state, removing public access from storage resources unless explicitly required, and revoking API keys and service account credentials that are no longer in use. Cloud environments accumulate abandoned resources steadily over time, and each one represents surface that no one monitors.
For server infrastructure, the principle of reducing to a minimal footprint, sometimes called server hardening, means turning off all services not required for the server’s specific function, closing all ports not required for legitimate traffic, removing compilers and scripting runtimes that an attacker could use for post-exploitation, and ensuring that no interactive login accounts exist beyond those with a documented operational requirement.
Network Segmentation and Attack Surface Reduction
Network segmentation reduces attack surface not by eliminating assets but by limiting which assets can communicate with which others, shrinking the blast radius of any individual compromise and removing lateral movement paths that an attacker would otherwise be able to follow freely.
A flat network, where every device can reach every other device without restriction, represents the maximum possible internal attack surface. An attacker who compromises any single endpoint on a flat network has potential access to every other system on it. Segmentation replaces this with a model where network zones are defined by function, sensitivity, or trust level, and traffic between zones is explicitly permitted or denied based on policy rather than allowed by default.
In practice, effective segmentation means separating production environments from development and staging, isolating OT and IoT devices from corporate IT networks, placing databases and internal services in zones that are not directly reachable from the internet-facing application tier, and enforcing micro-segmentation within cloud environments to limit east-west movement between workloads. Each boundary introduced into the network removes a class of lateral movement path and confines the impact of a successful initial compromise to the segment where it occurred.
The Ponemon Institute found that organizations with properly segmented networks experienced breaches that cost, on average, 17% less than those with flat architectures, a figure reflecting the lower blast radius, faster containment, and reduced data exposure that segmentation produces.
Identity and Access Controls That Shrink Exposure
The identity layer is one of the most productive places to reduce attack surface because identity-based exposures are pervasive, systematically underestimated, and directly actionable. Every account with more privilege than it needs, every credential that has not been rotated, and every service account whose permissions were granted for a project that ended years ago are active attack surfaces that cost nothing to eliminate.
Access reviews are the foundational practice. Systematically auditing user accounts, service accounts, and API keys against their actual usage patterns, and removing or downscoping permissions that exceed demonstrated need, directly reduces the identity attack surface without requiring any infrastructure change. Organizations that conduct access reviews quarterly rather than annually consistently find that a significant fraction of active permissions are either unused or no longer justified.
Multi-factor authentication on every externally reachable system removes an entire class of credential-based entry points. A leaked username and password combination, which may be circulating in breach data the organization is unaware of, cannot be used to authenticate if MFA is enforced. Given that credential exposure is among the most common initial access vectors in documented breaches, enforcing MFA is one of the highest-leverage single controls for reducing the identity attack surface.
Privileged account management adds a further layer by ensuring that administrative credentials are not used for day-to-day activities, that privileged sessions are logged and monitored, and that standing administrative access is replaced, wherever possible, with time-bound elevation. Each of these practices reduces the window during which high-value credentials are exposed to theft or misuse.
JIT Access, Zero Trust, and Least Privilege Approaches
Just-in-time (JIT) access, Zero Trust architecture, and the principle of least privilege represent three complementary approaches to reducing the identity- and access-based attack surface, each operating at a different level of the problem.
Least privilege is the foundational principle: every user, service, and process should have access only to the resources it needs to perform its specific function, and no more. In practice, this means scoping IAM policies tightly, avoiding wildcard permissions in cloud environments, and treating any permission grant as a deliberate decision that requires justification rather than a default that is simply never removed.
JIT access takes least privilege to its logical conclusion by eliminating standing access to sensitive systems entirely. Rather than granting an administrator permanent access to a production environment, access that exists whether or not any administrative task is being performed, JIT systems grant elevated access on demand for a defined duration and revoke it automatically when the session ends. The attack surface created by privileged credentials drops toward zero because there are no persistent privileged credentials to steal.
Zero Trust architecture provides the broader framework within which both operate. Rather than assuming that anything inside the network perimeter is trustworthy, Zero Trust requires continuous verification of every access request, regardless of origin, against identity, device health, and context signals before granting access to any resource. The architecture is designed around the assumption that the perimeter has already been breached, so internal network position provides no implicit trust. Every lateral movement attempt an attacker makes within a Zero Trust environment requires re-authentication and re-authorization, dramatically increasing the difficulty and visibility of post-compromise activity.
Firmware, Container, and Software Supply Chain Hardening
Three infrastructure categories, firmware, containers, and the software supply chain, represent some of the most consistently underinvested areas of attack surface reduction, and each has seen significant exploitation in recent years that reflects the gap between their risk profile and the security attention they receive.
Firmware hardening addresses the attack surface of software embedded in hardware devices, including network equipment, servers, storage systems, IoT devices, and physical security infrastructure. Firmware vulnerabilities are disproportionately dangerous because they persist below the operating system layer, survive reimaging, and are invisible to most security monitoring tools. Reducing the firmware attack surface means maintaining an inventory of all devices with embedded firmware, monitoring vendor advisories for firmware vulnerabilities, applying updates on a defined schedule, and turning off firmware-level features, such as remote management interfaces, that are not operationally required.
Container attack surface reduction operates primarily at the image layer. Container images built on bloated base images, particularly general-purpose Linux distributions that include compilers, package managers, and system utilities far beyond what the containerized application requires, carry a large software attack surface into every environment they are deployed into. Shifting to minimal base images, such as distroless or Alpine-based images, removes large volumes of unnecessary software from the container attack surface. Scanning images in the CI/CD pipeline for known vulnerabilities before they reach production ensures that vulnerable images are caught before deployment, not after.
Software supply chain hardening addresses the attack surface introduced by the third-party code, dependencies, and build tooling that modern applications depend on. The SolarWinds and XZ Utils incidents established that the software supply chain is a viable and increasingly targeted attack vector. Reducing this attack surface means maintaining a Software Bill of Materials (SBOM) for all applications, monitoring dependencies for newly disclosed vulnerabilities, verifying the integrity of build artifacts using code signing, and applying strict controls over who can modify build pipelines and deployment configurations.
How to Measure Reduction in Attack Surface Over Time
Measuring attack surface reduction requires establishing a baseline and systematically tracking change against it, because surface reduction without measurement is indistinguishable from surface reduction that was never achieved.
The most practical baseline metric is a count of exposed assets and services by category: externally reachable services, open ports, unmanaged endpoints, active credentials, misconfigured cloud resources, and known vulnerabilities in internet-facing systems, at a defined point in time. This baseline is not a one-time exercise; it is the starting point of a time series that the security program updates continuously and reports against on a defined cadence.
Reduction metrics that matter operationally include the number of assets removed from external exposure over a given period, the mean time to remediate a discovered exposure, the percentage of assets with confirmed security tool coverage versus those that fall outside any monitoring program, and the trend in the total number of critical and high-severity findings over time. A security program in which the total finding count is declining, mean remediation time is shrinking, and coverage gaps are being closed is measurably reducing its attack surface. One in which those metrics are stable or growing is not.
Reporting reduction metrics to security leadership and the board requires translating these operational figures into business language: fewer unmonitored assets means a smaller footprint for attackers to operate in; faster remediation means a shorter window of exploitability; declining critical findings means the organization is harder to breach than it was six months ago. The goal of measurement is not just operational feedback; it is the organizational evidence that the attack surface management program is producing a return on its investment.
Attack Surface Management vs. Other Security Disciplines
Attack surface management does not exist in isolation; it operates alongside and in relationship with a set of adjacent security disciplines that address overlapping problems from different angles. Understanding where each discipline begins and ends allows security teams to build programs that complement rather than duplicate one another.

Attack Surface Management vs. Vulnerability Management
Attack surface management and vulnerability management are the two disciplines most frequently conflated, and the confusion is understandable: both are concerned with organizational exposure, both produce findings that require remediation, and overlapping tool categories have historically addressed both. The distinction, however, is fundamental.
Vulnerability management operates on a known inventory. It scans assets the organization has already identified, tests them against databases of known vulnerabilities, and produces a prioritized list of CVEs requiring remediation. Its output is only as complete as the inventory it starts from. If an asset is not in scope for the vulnerability scanner, because it was provisioned without going through IT, because it belongs to a subsidiary that was never onboarded into the program, or because it was simply forgotten, it receives no scan and produces no findings, regardless of how many critical vulnerabilities it carries.
Attack surface management starts one step earlier. Its first question is not “what vulnerabilities exist on our assets?” but “what assets do we have, and which of them are reachable by an attacker?” ASM discovers the inventory that vulnerability management then needs to operate on. An asset unknown to the vulnerability program is not safe; it is unmonitored. ASM surfaces those assets and closes the coverage gap that vulnerability management, by design, cannot see.
The operational relationship between them is sequential and complementary. ASM provides continuous asset discovery and visibility into external exposure; vulnerability management provides deep technical analysis of the weaknesses within that inventory. Organizations that run vulnerability management without ASM are scanning a subset of their actual attack surface. Those that run ASM without vulnerability management have an accurate exposure map but limited insight into which specific weaknesses within it are most urgently exploitable. Gartner’s guidance on exposure management positions the two as foundational components of the same program, not competing alternatives.
Exposure Management vs. Attack Surface Management
Exposure management is a broader strategic framework that subsumes attack surface management as one of its components. The distinction is one of scope rather than approach.
Attack surface management focuses on discovery and visibility: which assets exist, which are reachable, and what is currently exposed. It is fundamentally an inventory and monitoring discipline. Exposure management encompasses ASM but extends beyond it, incorporating vulnerability prioritization, threat intelligence context, business impact assessment, and remediation validation into a unified program that not only identifies exposure but systematically reduces it within a defined risk tolerance.
Gartner’s Continuous Threat Exposure Management (CTEM) framework, introduced in 2022, provides the most widely cited articulation of exposure management as a discipline. CTEM describes a five-stage cycle: scoping, discovery, prioritization, validation, and mobilization, in which attack surface management provides the discovery foundation. The prioritization and validation stages add dimensions that ASM alone does not address: which exposures are actually exploitable by realistic threat actors, which have been confirmed through adversarial simulation, and which represent the highest business risk given the organization’s specific context.
In practical terms, a mature security program treats ASM as the input layer that feeds a broader exposure management function. The attack surface tells you what exists and what’s exposed; exposure management tells you what to fix first and verifies that the fixes actually worked.
Attack Surface Management vs. Threat Intelligence
Attack surface management and threat intelligence answer different questions that become significantly more powerful when combined. ASM asks: where are we exposed? Threat intelligence asks: who is targeting organizations like us, with what techniques, and through what initial access vectors?
In isolation, each discipline has a blind spot. An ASM program without threat intelligence context produces an undifferentiated list of exposures, with no information on which are actively targeted by real threat actors. A threat intelligence program without ASM context produces detailed profiles of adversary behavior with no visibility into whether the organization’s own attack surface contains the entry points those adversaries prefer to exploit.
The integration of the two closes both gaps. When threat intelligence identifies that a specific threat actor group is actively exploiting a particular vulnerability type, unpatched VPN gateways, exposed RDP services, or a specific CVE in a widely used web framework, an organization with a current ASM inventory can immediately determine whether its own attack surface contains the relevant exposure and prioritize remediation accordingly. The intelligence becomes actionable rather than informational.
This integration is increasingly reflected in how ASM platforms are built. Leading platforms incorporate threat intelligence feeds that tag discovered exposures against active exploitation signals, CVE severity in the context of real-world attack campaigns, and indicators that specific assets in the customer’s inventory match the targeting profile of documented threat actor groups. The output is an attack surface map annotated with adversarial context, a materially different product from either discipline alone.
ASM vs. CAASM vs. EASM: Which Does What?
The three-way comparison between ASM, CAASM, and EASM is one of the most common points of confusion in the discipline, partly because the terms are used inconsistently across vendors and analysts and partly because the boundaries between them are genuinely porous in practice.
ASM (attack surface management) is the parent category. It describes the overall discipline of managing organizational exposure across all asset types, from any perspective, using any combination of discovery and monitoring techniques. CAASM and EASM are both subcategories of ASM, distinguished by their data sources, their perspective, and the specific visibility problems they are designed to solve.
EASM operates externally, using passive reconnaissance against public sources to discover internet-facing assets from the attacker’s perspective. It requires no internal access and no pre-existing inventory. Its defining value is finding what the organization doesn’t know it’s exposing to the public internet, the unknown unknowns of the external attack surface.
CAASM operates internally, integrating with existing security and IT tools to aggregate and normalize asset data into a unified inventory. Its defining value is eliminating the fragmentation of internal asset data across siloed systems, producing a single authoritative view of every asset the organization owns, including those with no external exposure.
The decision between them is not an either-or choice. EASM tells you what attackers can see. CAASM tells you everything that exists. Organizations at early stages of program maturity typically start with EASM because external exposure represents the most immediate, actionable risk. As programs mature, CAASM adds an internal visibility layer that completes the overall inventory. Full-spectrum ASM, combining both perspectives, is the goal of a mature program.
Breach and Attack Simulation vs. ASM
Breach and attack simulation (BAS) and attack surface management operate at different stages of the security program lifecycle and serve different validation purposes. However, they are increasingly used together as complementary capabilities.
Attack surface management is a discovery and monitoring discipline. It identifies what is exposed and tracks changes to that exposure over time. It does not, by itself, confirm whether any identified exposure is actually exploitable in practice; it only confirms that it exists and is reachable.
Breach-and-attack simulation fills that validation gap. BAS platforms continuously execute simulated attack scenarios, phishing campaigns, lateral movement chains, and data exfiltration attempts against the organization’s actual environment, testing whether existing security controls detect and prevent the techniques real threat actors use. The output is not a list of exposures but a measurement of control effectiveness: which attacks would succeed, which would be detected, and which would be blocked.
The integration of ASM and BAS produces a prioritization capability that neither provides on its own. ASM surfaces the exposures; BAS tests whether they are genuinely exploitable given the organization’s current control posture. Existing controls block an exposure that ASM identifies as high-severity but that BAS confirms can be deprioritized relative to one that both disciplines flag as simultaneously exposed and exploitable. This combination, continuous discovery validated by continuous simulation, represents the closest approximation to an attacker’s actual perspective that most organizations can operationalize at scale.
ASM and XDR: How They Work Together
Extended detection and response (XDR) and attack surface management address the same threat landscape from opposite temporal positions. ASM operates before an attack, identifying and reducing the entry points available to an adversary. XDR operates during and after an intrusion, detecting, correlating, and responding to attacker activity across endpoints, networks, cloud workloads, and identity systems.
The integration between them is not just conceptual. An ASM platform that maintains a continuously updated inventory of internet-facing assets, cloud resources, and exposed services provides XDR with the asset context it needs to accurately correlate detections. When an XDR platform receives an alert involving an IP address or hostname, knowing whether that asset is a known production server, an unmanaged development environment, or a shadow IT resource that security has no record of materially changes the severity assessment and the appropriate response.
In the other direction, XDR telemetry enriches ASM prioritization. When an XDR platform detects reconnaissance activity, port scanning, credential stuffing attempts, or unusual authentication patterns against specific assets in the organization’s inventory, those assets should immediately move to the top of the ASM remediation queue. The attacker’s behavior itself is a signal of which parts of the attack surface are under active pressure.
Organizations that treat ASM and XDR as separate programs operating in parallel leave this integration value unrealized. Those that connect them, feeding ASM inventory data into XDR for detection context, and feeding XDR threat signals back into ASM for exposure prioritization, operate a security program in which prevention and detection reinforce each other continuously rather than functioning as independent layers with a gap between them.
How to Evaluate Attack Surface Management: Key Criteria and Questions
Choosing an attack surface management approach is not primarily a product decision; it is a program design decision. The right answer depends on where your organization sits in its security maturity, which visibility gaps pose the greatest risk, and what operational capacity exists to act on findings once they surface.

What Capabilities Should an ASM Solution Cover?
A capable attack surface management solution needs to address the full lifecycle of exposure, from initial discovery through to remediation, rather than excelling at one phase while leaving others to manual processes or separate tools.
Discovery breadth is the first evaluation criterion. The platform must be able to find assets the organization does not have on record, not just enumerate the ones it does. That requires integrating with a wide range of passive discovery sources: certificate transparency logs, passive DNS, WHOIS and ASN data, code repositories, internet indexing services, dark web forums, and breach data corpora. A platform that scans only known IP ranges or pre-provided asset lists is a vulnerability scanner operating on an incomplete inventory, not a genuine ASM solution.
Continuous monitoring, not periodic scanning, is the second requirement. The attack surface changes whenever a developer deploys a new service, a cloud configuration is modified, or a credential appears in a new breach dump. A platform that runs weekly or monthly scans produces snapshots of a moving target. The operational standard for mature ASM is a detection pipeline measured in minutes: new exposures surface in near real time rather than accumulating undetected between scheduled scan cycles.
Risk prioritization determines whether findings are actionable. Most organizations have more exposures than they can remediate simultaneously. A platform that produces an undifferentiated list of findings at equal severity generates alert fatigue and slows remediation. Effective prioritization incorporates multiple signals: CVSS score, CISA Known Exploited Vulnerabilities catalog membership, exploit-in-the-wild intelligence, asset criticality based on business context, and blast radius modeling based on asset connectivity. The output should be a queue where the item at the top genuinely represents the highest risk, not simply the most recently discovered finding.
Workflow integration determines whether the platform produces action or reports. Findings that require a security analyst to context-switch to a separate ASM portal, manually triage a finding, and then re-enter it into Jira or ServiceNow add friction, slowing remediation and reducing program adoption. Native integrations with the ticketing, communication, and SIEM platforms the security team already uses, with enough context in each routed finding that the recipient can act without a separate investigation, are an operational requirement, not a nice-to-have.
AI-powered attack surface management adds a capability layer that is increasingly distinguishing mature platforms from legacy ones. Machine learning applied to asset attribution improves the accuracy of determining which discovered assets belong to the target organization versus neighboring infrastructure. Anomaly detection applied to the asset graph surfaces behavioral drift- a service that has suddenly started accepting connections on an unusual port, a certificate issued from an unexpected authority- that rule-based monitoring would miss. AI-assisted risk scoring that incorporates real-time threat intelligence context produces prioritization that reflects actual attacker behavior rather than static severity ratings.
EASM vs. CAASM vs. Continuous ASM: What Does Your Organization Actually Need?
The choice between EASM, CAASM, and a continuous ASM posture is not a vendor selection question; it is a scoping question that should be answered by analyzing where your most significant visibility gaps actually live.
If your primary concern is unknown external exposure, assets you don’t know are reachable from the internet, credentials circulating in breach data, cloud resources misconfigured to allow public access, then EASM is the right starting point. It requires no internal integration, deploys quickly, and begins producing findings within hours of onboarding. It is particularly well suited to organizations that have grown through acquisition, operate complex multi-domain environments, or have reason to believe their external footprint is larger than their asset inventory reflects.
If your primary concerns are internal asset visibility, security tool coverage gaps, unmanaged endpoints, shadow IT accumulating in cloud environments, and fragmented asset data across siloed systems, then CAASM addresses the problems EASM cannot reach. It operates on internal data sources and produces the unified inventory that vulnerability management, patch management, and security operations all depend on to function effectively. CAASM investment is most justified when organizations already have reasonable external visibility but lack confidence in their internal asset inventory.
Continuous ASM is less a product category than a program commitment: the decision to treat attack surface management as an always-on operation rather than a periodic exercise. It requires platforms that support real-time detection pipelines, asset graph updates that reflect the current state rather than last week’s, and alerting thresholds calibrated to surface genuine signal without generating noise that overwhelms the team responding to it. Most organizations should aspire to this posture, regardless of whether they lead with EASM or CAASM, because a continuously running discovery program is structurally more valuable than one that produces periodic reports.
For organizations evaluating platforms across all three categories, the practical question is: what exposure scenario would cause the most damage if it remained undetected for 60 days? The answer to that question almost always points directly to which category of visibility should be prioritized first.
Open Source vs. Commercial Attack Surface Management
Open source attack surface management tooling exists and has genuine value, but it occupies a different operational position from commercial platforms and serves a different organizational profile.
The open source ecosystem for ASM is built primarily around individual discovery tools rather than integrated platforms. Amass, developed by OWASP, is the most widely used open-source tool for subdomain enumeration and external attack surface discovery. It performs DNS enumeration, certificate transparency log analysis, and passive reconnaissance across multiple data sources. Subfinder, httpx, and nuclei from ProjectDiscovery provide complementary capabilities for subdomain discovery, HTTP probing, and vulnerability detection, respectively. Tools like theHarvester collect email addresses, hostnames, and organizational data from public sources. SpiderFoot aggregates OSINT from dozens of sources into a single investigation interface.
The limitation of open-source tooling is not capability; individual tools like Amass are genuinely powerful, but integration, operationalization, and scale are the challenge. Running open-source ASM effectively requires assembling a pipeline from multiple tools, building the infrastructure to run them continuously, developing the logic to deduplicate and normalize their outputs, and constructing workflow integrations that route findings to the people who need to act on them. For a security engineering team with the capacity to build and maintain that infrastructure, open-source ASM can provide comprehensive coverage at a low direct cost. For most security teams, the engineering overhead required to operationalize open-source tooling exceeds the cost difference compared to a commercial platform.
Free attack surface management tools offered by commercial vendors occupy the middle ground. Several established platforms offer free tiers or free scan capabilities that provide genuine external exposure visibility without a subscription commitment, useful for initial assessment, for organizations with limited budgets, or for validating the value of ASM before committing to a full program. The limitations of free tiers are typically scope: they may cover a single domain, provide point-in-time rather than continuous monitoring, or omit breach data and dark web intelligence sources that make continuous monitoring genuinely comprehensive.
Attack Surface Management Market Overview
The attack surface management market has grown from an emerging category into an established segment of the enterprise security landscape over the past four years, driven by the combination of expanding digital attack surfaces, high-profile breaches initiated through unknown external assets, and increasing board-level attention to cyber exposure as a business risk.
Gartner formally recognized EASM as a distinct technology category in its 2021 Hype Cycle for Security Operations and has continued to develop its coverage through subsequent iterations, positioning attack surface management as a foundational component of its Continuous Threat Exposure Management (CTEM) framework. The inclusion of ASM within CTEM, alongside breach and attack simulation, vulnerability prioritization, and remediation validation, reflects Gartner’s view that managing exposure requires a program rather than a point solution, with ASM providing the discovery foundation on which the rest of the program depends.
Forrester has similarly elevated ASM in its security research, covering external attack surface management in its Wave evaluations and identifying continuous asset visibility as a top priority for security leaders responding to the expansion of cloud and remote work infrastructure. Both firms identify a market consolidating around a smaller number of platforms capable of delivering integrated discovery, monitoring, prioritization, and workflow integration, rather than the earlier generation of standalone scanning tools that addressed one phase of the ASM lifecycle in isolation.
The attack surface management market size was valued at approximately $1.5 billion in 2024 and is projected to grow at a compound annual growth rate exceeding 30% through 2029, according to multiple independent market research estimates. This growth rate reflects both the expansion of the problem the market addresses and the growing recognition that managing the attack surface requires dedicated tooling rather than manual processes or repurposed vulnerability scanners.
The vendor landscape spans several segments: pure-play EASM platforms built specifically for external discovery and monitoring; CAASM platforms focused on internal asset aggregation and coverage gap analysis; broader exposure management platforms that combine ASM with vulnerability prioritization and BAS capabilities; and large security vendors that have incorporated ASM modules into existing platform suites. The right evaluation criterion across all of them remains constant: does the platform close the specific visibility gap that represents your organization’s most significant unmanaged risk, and does it integrate with the workflows your team already uses to act on findings?
Why Attack Surface Management Matters: Real-World Scenarios and Use Cases
Attack surface management moves from theory to operational necessity the moment you examine how actual breaches begin. In the overwhelming majority of documented incidents, the initial access point was an asset the victim organization either didn’t know was exposed, didn’t know existed, or knew about but had deprioritized for remediation. ASM is the discipline that closes that gap systematically rather than waiting for an incident to reveal it.

Enterprise Attack Surface Management at Scale
For large enterprises, attack surface management is not simply a visibility problem; it is a governance and coordination problem at a scale that makes manual approaches structurally unworkable. An organization with dozens of business units, hundreds of domains, multiple cloud providers, and a portfolio of acquired companies may have tens of thousands of internet-facing assets distributed across infrastructure provisioned by different teams, under different security standards, spanning decades of technology investment.
The defining challenge of enterprise attack surface management is not discovery; modern ASM platforms can enumerate a large external footprint in hours. It is ownership attribution: determining which business unit, engineering team, or subsidiary is responsible for each discovered asset, so that findings can be routed to someone with the authority and context to remediate them. An enterprise that surfaces 2,000 previously unknown assets and has no mechanism to assign ownership has transformed one visibility problem into 2,000 accountability problems.
Mature enterprise ASM programs address this through a combination of automated attribution, using domain registration data, certificate ownership, cloud account tagging, and content fingerprinting to assign assets to organizational units, and a governance layer that defines escalation paths for unattributed assets and accountability metrics that business unit leaders are measured against. The security function sets the standard and monitors compliance; the business units own the remediation. This division is essential at scale because the security team rarely has the context or authority to remediate assets it didn’t build.
Mergers and acquisitions introduce a specific enterprise ASM challenge with a defined timeline and well-understood consequences. Acquired companies bring unknown infrastructure, legacy security practices, and an attack surface that has often received minimal attention during the transaction process. Post-acquisition ASM, running comprehensive external discovery against the acquired entity’s domain portfolio immediately after close, consistently surfaces material exposures that were not identified during due diligence and that represent real risk to the acquiring organization from the moment the deal closes.
Ransomware and Attack Surface Exposure
The relationship between attack surface management and ransomware defense is direct and well-documented. Ransomware operators do not breach organizations through sophisticated zero-day exploits as a primary tactic; they gain initial access through exposed, unpatched, or misconfigured assets on the victim’s attack surface that have not been prioritized for remediation.
The Ransomware Task Force and multiple incident response firms have consistently identified the same initial access vectors across the majority of ransomware incidents: exposed RDP services with weak or reused credentials, unpatched VPN gateways running firmware with known critical vulnerabilities, phishing campaigns exploiting credentials already circulating in breach data, and public-facing web applications running outdated software with documented exploits. Every one of these is an attack surface management problem before it becomes a ransomware incident.
Coveware’s quarterly ransomware reports have repeatedly found that RDP compromise and software vulnerabilities in internet-facing systems account for the majority of confirmed ransomware initial access vectors, attack surface exposures that a functioning ASM program would identify, monitor, and drive toward remediation before they are weaponized. The implication is significant: a material fraction of successful ransomware attacks are not failures of detection or response but failures of exposure management. The attacker used a door that was left open.
Attack surface management applied to ransomware defense therefore focuses on the specific exposure categories that ransomware operators prefer: internet-facing services running outdated software, exposed authentication interfaces without MFA enforcement, credentials appearing in breach data before they are revoked, and cloud misconfigurations that could serve as initial footholds. Continuous monitoring of these specific exposure types, with prioritized alerting and defined remediation SLAs, directly reduces the probability of ransomware initial access without requiring any change to detection or response capabilities.
ASM for Remote Work Environments
The shift to remote and hybrid work permanently expanded the attack surface of most organizations in ways that traditional perimeter-based security models were not designed to accommodate. When employees work from home, corporate traffic and corporate assets move outside the controlled network environment that most security architectures assumed as their foundation.
The attack surface implications of remote work are specific and measurable. VPN gateways and remote access infrastructure move from internal to internet-facing services, making them targets for the same reconnaissance and exploitation activities directed at any other public-facing system. Home networks introduce endpoint risk that corporate security controls cannot govern: routers running default credentials, shared network segments with personal devices, and ISP-assigned IP addresses that change unpredictably. Personal devices used for work, even in BYOD programs with mobile device management, represent an endpoint attack surface that corporate security teams have limited visibility into and limited ability to harden.
Credential exposure significantly compounds the problem of the remote work attack surface. Employees working across personal and corporate accounts on the same devices increase the likelihood that corporate credentials appear in consumer data breaches. This risk is invisible to the organization unless it actively monitors breach data for employee credential exposure. An employee whose personal email account shares a password with their corporate SSO creates an attack surface that no network-based control can detect.
ASM programs adapted for remote work environments expand their monitoring scope to include the remote access infrastructure itself, VPN concentrators, Citrix environments, RDP gateways, and web-based remote access portals, all of which are high-priority assets requiring continuous vulnerability monitoring and rapid patch deployment. They also extend credential monitoring to cover the full domain of employee email addresses, not just corporate accounts, recognizing that personal credential exposure is a legitimate corporate risk in a world where work and personal digital lives share the same devices.
Continuous ASM in Modern SecOps Workflows
The integration of attack surface management into security operations represents a maturation of the discipline from a periodic program function into a continuous operational input. In modern SecOps workflows, ASM is not a quarterly report delivered to a committee; it is a live data feed that informs detection prioritization, investigation context, and response decisions in near real time.
The practical integration point between ASM and security operations is the SIEM or SOAR platform that sits at the center of most SecOps functions. When ASM inventory data flows into the SIEM, every alert generated by the detection layer can be enriched with asset context: is this the IP address of a known production server or an unmanaged shadow IT resource? Is this domain a legitimate subsidiary or a lookalike registered last week? Is this authentication attempt targeting an asset that was flagged as critically exposed in the ASM feed yesterday? These questions change the triage decision, and the ability to answer them automatically, without a separate investigation, compresses the mean time to respond.
Attack surface management also changes the economics of threat hunting. Security analysts conducting proactive hunting campaigns typically start from threat intelligence about adversary techniques and work backward to determine which assets in the environment are relevant. An accurate, current ASM inventory makes this process significantly faster: rather than querying multiple internal systems to determine what RDP-exposed assets exist in the environment, the analyst queries the ASM platform and receives an authoritative, current answer in seconds. The inventory becomes the foundation of hunting rather than the first problem the hunter has to solve.
The attack surface management lifecycle- discover, inventory, monitor, prioritize, remediate, and measure- maps directly onto the SecOps operational rhythm when it is properly integrated. Discovery feeds the asset inventory that detection depends on. Monitoring feeds the alert queue that triage operates from. Prioritization feeds the remediation backlog that engineering teams work from. Measurement feeds the reporting that security leadership and the board consume. Each stage produces output that the next stage requires, and the whole cycle runs continuously rather than on a quarterly schedule.
The Role of ASM in Incident Response and Red Teaming
Attack surface management intersects with both incident response and red teaming at a stage that most organizations underinvest in: the preparation and scoping phase that determines how effectively each discipline can operate when it is called upon.
In incident response, the quality of the asset inventory available at the moment an incident begins is one of the strongest predictors of how quickly the response team can contain it. When a suspicious authentication event is detected against an unknown asset, the first question the responder asks is: what is this system, who owns it, what data does it hold, and what other systems can it reach? If those questions take hours to answer because the asset is not in any inventory, the attacker has hours of uncontested dwell time while the response team reconstructs context that a current ASM inventory would have provided immediately. IBM’s Cost of a Data Breach Report found that organizations with high levels of IR planning and testing reduced breach costs by an average of $2.66 million compared to those without, a figure that reflects, in part, the value of having accurate asset context available when it is needed most.
Red teaming and ASM are designed to inform each other in both directions. The first phase of a red team engagement, reconnaissance, is structurally identical to what an EASM platform does continuously. A red team conducting external reconnaissance against a target organization will discover the same forgotten subdomains, exposed staging environments, leaked credentials, and misconfigured cloud resources that a well-configured ASM program surfaces automatically. Organizations that run continuous ASM before commissioning a red team engagement consistently find that the engagement produces fewer critical surprises, not because the red team is less capable, but because the most obvious exposures have already been found and remediated.
In the other direction, red team findings that reveal exposures not surfaced by the ASM program are diagnostic signals about coverage gaps. If a red team discovers an internet-facing asset that the ASM platform did not identify, the question is not just how to remediate that specific asset; it is what characteristic of that asset caused it to fall outside the platform’s discovery scope, and how many similar assets might share that characteristic. Red team findings, when fed back into the ASM program as calibration data, make the continuous monitoring capability more complete with each engagement.
Challenges of Attack Surface Management (And How to Overcome Them)
Attack surface management is not a problem that yields to a one-time solution. The challenges that make it difficult are structural; they are built into the way modern organizations operate, adopt technology, and grow, which means overcoming them requires program design that accounts for continuous change rather than tools that produce a fixed answer.

Shadow IT and Unknown Assets
Shadow IT is the most persistent challenge in attack surface management because it is not an aberration; it is a predictable byproduct of how modern organizations work. When a marketing team needs a microsite in two days, when a developer spins up a cloud instance to test a feature, when a sales team adopts a SaaS tool without going through IT procurement, they are extending the organization’s attack surface without extending its security coverage. The asset exists, it is reachable, and no one with security responsibility knows it is there.
The difficulty is that shadow IT grows in direct proportion to organizational productivity. Teams that move fast provision resources fast, and the gap between provisioning speed and security review speed is where unknown assets accumulate. A 2023 study by Dynatrace found that security teams are aware of only 69% of their internet-facing applications on average, meaning nearly one in three public-facing assets exists outside any formal security program.
Overcoming shadow IT requires treating asset discovery as a continuous process rather than an annual audit. The only reliable way to find unknown assets is to look for them from the outside, the same way an attacker would, on a cadence that is faster than the rate at which new assets appear. Organizations that run continuous external discovery across their full domain portfolio, not just the assets IT has on record, surface shadow IT as it is created, rather than months later, when it has already been exploited or has accumulated significant technical debt.
Rapidly Expanding Cloud and SaaS Attack Surfaces
The cloud and SaaS attack surface is structurally different from the on-premises attack surface it has partially replaced, and the difference is almost entirely unfavorable from a management perspective. On-premises infrastructure changes slowly; cloud infrastructure changes constantly. A server provisioned in a data center stays provisioned until someone physically decommissions it; a cloud resource can be created, modified, exposed, and forgotten in the same afternoon by someone who has never spoken to the security team.
SaaS adoption compounds the expansion problem by introducing a new category of attack surface that the security team may lack visibility into. When an employee authenticates to a third-party SaaS application using corporate SSO credentials, that application gains access to the data and permissions associated with that identity, potentially including email, calendar, file storage, and directory information, without any security review of the application’s own posture or data-handling practices. The SaaS attack surface is not just the applications themselves, but also the permissions, OAuth tokens, and identity federation relationships they accumulate.
The practical response to rapidly expanding cloud and SaaS attack surfaces is to enforce policy at the provisioning layer rather than remediate after the fact. Infrastructure-as-code scanning, cloud security posture management, and SaaS security posture management tools push security requirements into the deployment pipeline, preventing misconfigurations from entering the environment rather than detecting them after they have been running unmonitored for weeks. The goal is to make the secure path the easy path, so that teams provisioning resources quickly are automatically guided toward configurations that don’t create unnecessary exposure.
Lack of Continuous Visibility
The gap between periodic scanning and continuous visibility is not a matter of degree; it is a qualitative difference in the kind of security program the organization is operating. A program that scans monthly produces a picture of the attack surface as it existed on scan day. Everything that happened in the intervening thirty days- new assets provisioned, configurations changed, credentials leaked, certificates expired- is invisible until the next scan cycle runs. In active cloud environments, that thirty-day window can contain hundreds of configuration changes and dozens of new assets.
The challenge of achieving continuous visibility is not primarily technical; the tools to run continuous discovery are available and commercially viable. The challenge is operational: continuous monitoring generates a continuous stream of findings, and a security team without the capacity to triage and act on findings in near real time will quickly develop a backlog that defeats the purpose of continuous detection. Continuous visibility without continuous response is an alert queue that no one trusts.
Overcoming this challenge requires designing the monitoring program around the team’s actual response capacity, not the theoretical maximum sensitivity of the detection tooling. This means tuning alert thresholds to surface genuine signal rather than every low-confidence finding, building automated triage workflows that route findings to the right owner without requiring manual review of every alert, and establishing defined SLAs for response by severity level so that the team has a clear standard to operate against rather than an undifferentiated flood of notifications.
Alert Fatigue and Risk Prioritization
Alert fatigue is the downstream consequence of attack surface management programs that find everything but prioritize nothing. When every discovered exposure generates an alert at equal severity, the volume of notifications exceeds the team’s capacity to respond, trust in the alerting system erodes, and the most critical findings receive the same attention as the least critical ones, which is to say, not enough.
The root cause is prioritization frameworks that rely too heavily on a single dimension. CVSS scores describe the technical severity of a vulnerability in isolation; they do not account for whether the affected asset is a revenue-generating production system or an abandoned test environment, whether the vulnerability has a working exploit actively used in the wild, whether the asset is reachable from the internet or only from an internal network segment, or whether it is currently being targeted by documented threat actor activity. A critical CVSS score on an internal development server that has no external exposure is materially less urgent than a medium CVSS score on a public-facing authentication portal targeted by active exploitation campaigns.
Effective prioritization in mature ASM programs incorporates four dimensions simultaneously: technical severity, exploitability context drawn from threat intelligence and active exploitation signals, asset criticality weighted by business impact, and exposure scope determined by whether the asset is internet-facing and reachable from outside the organization. Findings that score high across all four dimensions go to the top of the remediation queue regardless of their absolute CVSS score. Findings that score high on technical severity but low on all other dimensions are triaged differently. This multidimensional approach reduces alert noise, builds analyst trust in the queue, and directs remediation effort toward the exposures that represent the highest actual risk rather than the highest theoretical score.
Multi-Cloud and Hybrid Environment Complexity
Multi-cloud and hybrid environments are the operating reality for most large organizations and the source of some of the most persistent challenges in attack surface management. The problem is not that any individual cloud environment is difficult to manage in isolation; native security tooling for AWS, Azure, and Google Cloud is genuinely capable within its own boundary. The problem is that the boundaries don’t align, the tools don’t communicate, and the attack surface spans all of them simultaneously.
Each cloud provider uses a different identity model, configuration syntax, logging formats, and security services with varying coverage characteristics. A security policy that prevents public access to AWS S3 buckets must be implemented differently in Azure Blob Storage and in Google Cloud Storage. A misconfiguration that AWS Security Hub would detect may go unnoticed by Microsoft Defender for Cloud unless the organization has explicitly configured cross-environment monitoring. The cumulative effect is a set of visibility gaps at every boundary between environments, and it’s precisely there that attackers look for inconsistencies that allow lateral movement.
Hybrid environments add the on-premises layer to this complexity, introducing a category of assets that cloud-native ASM tooling was not designed to cover and that on-premises tools cannot extend into cloud environments without significant integration work. The VPN gateways, Active Directory infrastructure, and legacy application servers that connect on-premises networks to cloud environments are particularly high-risk because they sit at the intersection of both worlds: they are internet-facing enough to be targeted, complex enough to misconfigure, and old enough to carry vulnerabilities that modern cloud-native infrastructure would not.
The practical response is a provider-agnostic ASM layer that sits above individual cloud environments, normalizes findings, enforces consistent policy concepts, and provides unified visibility regardless of where the underlying asset is hosted. This abstraction layer does not replace native cloud security tooling; it complements it by providing the cross-environment view that native tools cannot provide on their own.
Supply Chain and Third-Party Blind Spots
The supply chain attack surface is the segment of organizational exposure that is hardest to manage because the organization has the least control over it. A vendor with privileged access to corporate systems, a SaaS provider that processes sensitive data, and a software dependency embedded in a production application each extend the effective attack surface beyond the organization’s own infrastructure into environments it cannot directly audit, monitor, or harden.
The challenge is structural. Standard vendor risk management processes, security questionnaires, annual assessments, and contractual security requirements produce point-in-time attestations that describe a vendor’s security posture at the time the questionnaire was completed, not as it is today. A vendor that passes a security review in January and experiences a breach in March represents a supply chain risk that no questionnaire-based program will detect in the intervening period.
Continuous monitoring of vendor exposure is the only approach that addresses this gap at operational speed. Monitoring the external attack surface of key vendors, their internet-facing assets, exposed credentials, dark web mentions, and detected breach events provides early warning of supply chain risk that internal processes cannot generate. When a tier-one vendor’s credentials appear in a fresh breach corpus, when a software provider’s build infrastructure shows signs of compromise, when a SaaS platform’s certificate infrastructure changes unexpectedly, these are signals that the organization’s own attack surface may be affected through its supply chain relationships. Continuous monitoring surfaces them in time to act rather than in time to respond.
The SolarWinds compromise remains the benchmark case: an attacker who inserted malicious code into a trusted software update reached thousands of downstream organizations whose own security programs gave them no indication that anything was wrong. The lesson is not that supply chain attacks are undetectable; it is that detecting them requires monitoring the supply chain as part of the attack surface, not treating it as an external risk managed entirely through contracts and questionnaires.
See Your Full Attack Surface, Including What’s Hidden on the Dark Web
Understanding attack surface management is the first step. Knowing exactly what your organization is exposing right now is what makes that understanding actionable.
Your attack surface doesn’t stop at visible infrastructure. Leaked credentials circulating on dark web markets, employee data in breach dumps, and compromised accounts in stealer logs are all part of your exposure profile, and they are the entry points that attackers prioritize precisely because most organizations have no visibility into them.
DeXpose closes both gaps simultaneously.
Map your external attack surface. DeXpose’s Attack Surface Mapping service discovers every internet-facing asset your organization exposes- domains, subdomains, cloud workloads, APIs, and infrastructure your team has lost track of- then monitors for changes continuously so that new exposures surface in minutes, not months. An offensive security analyst reviews every critical finding before it reaches your team, which means the findings you receive are confirmed, exploitable, and prioritized for action.
Find out what’s already exposed on the dark web. Before any attacker engages with your infrastructure directly, they check what’s already available: leaked credentials, breach data, malware logs, and organizational exposure data circulating across dark web markets and forums. DeXpose’s Free Dark Web Report gives you an immediate, comprehensive picture of your organization’s dark web exposure, covering markets, stealer logs, and public breaches, at no cost and with no commitment required.
Get Your Free Dark Web Report →
DeXpose is built by offensive security practitioners for the teams defending real organizations. Start with visibility. Start for free.
Frequently Asked Questions (FAQ’s)
What is attack surface management in simple terms?
Attack surface management is the continuous process of finding every digital entry point an attacker could use to access your organization, and systematically reducing, monitoring, and securing those points before they are exploited. It covers known assets, unknown assets, cloud infrastructure, credentials, and third-party connections simultaneously.
What are the main types of attack surfaces?
The main types are physical (endpoints, hardware, removable media), digital (applications, APIs, web services), network (exposed ports and protocols), cloud (SaaS, IaaS, multi-cloud infrastructure), identity (credentials, accounts, access permissions), IoT and OT (connected devices and operational systems), and supply chain (vendors and third-party software). Each type carries distinct exposure patterns and requires different monitoring approaches.
What is the difference between an attack surface and an attack vector?
An attack surface is the complete set of entry points an attacker could target, the total terrain of organizational exposure. An attack vector is the specific method used to exploit one of those points, such as phishing, SQL injection, or brute-force credential attack. The surface is the landscape; the vector is the route through it.
How does external attack surface management (EASM) work?
EASM works by simulating attacker reconnaissance from outside the organization, scanning certificate transparency logs, passive DNS records, code repositories, breach data, and dark web sources to discover every internet-facing asset attributable to the target. It requires no internal access, begins with only a domain name or company identifier, and runs continuously so that new exposures are detected in near real time rather than on a scheduled scan cycle.
What does CAASM stand for, and how does it differ from EASM?
CAASM stands for Cyber Asset Attack Surface Management. Where EASM discovers external exposure by looking outward from the internet, CAASM builds a complete internal asset inventory by aggregating data from existing security and IT tools, endpoint agents, cloud APIs, CMDBs, and identity systems to surface coverage gaps and unmanaged assets with no external exposure. The two disciplines are complementary: EASM finds what attackers can see; CAASM finds everything that exists.
How do you reduce an attack surface?
Attack surface reduction means systematically eliminating unnecessary exposure: disabling services and ports that aren’t operationally required, enforcing least-privilege access across all accounts and cloud resources, removing or decommissioning assets that are no longer active, patching internet-facing systems on an accelerated timeline, and monitoring continuously for new exposures as infrastructure changes. Every entry point eliminated permanently removes an entire category of potential attack vectors.
How is attack surface management different from vulnerability management?
Vulnerability management scans a known inventory of assets for specific weaknesses; it can only find vulnerabilities in assets it already knows about. Attack surface management starts one step earlier by discovering which assets exist in the first place, including those no one has on record. ASM provides the complete inventory that vulnerability management needs to operate on; without it, vulnerability programs scan only a subset of the actual attack surface, remaining blind to everything outside their known scope.
What are the best attack surface management tools in 2025?
The leading attack surface management platforms in 2025 include Palo Alto Cortex Xpanse, Microsoft Defender EASM, Tenable, CrowdStrike Falcon Surface, Censys, and Bitsight for external discovery and monitoring, alongside CAASM-focused platforms such as Axonius and JupiterOne for internal asset visibility. The right choice depends on whether the organization’s primary gap is external exposure, internal asset coverage, or both, and how deeply the platform integrates with existing security workflows.
What is attack surface intelligence?
Attack surface intelligence is the enriched, contextualized data produced by combining external asset discovery with threat intelligence signals, active exploitation campaigns, dark web activity, breach data, and adversary targeting patterns to produce a prioritized picture of organizational exposure. It goes beyond a list of assets and vulnerabilities to answer the question that matters operationally: which of our exposures are under active threat right now, and which should we fix first?
Why is minimizing attack surface a cybersecurity principle?
Minimizing the attack surface is a foundational security principle because every unnecessary entry point is a liability that provides no organizational benefit while offering an attacker options. Reducing the surface eliminates entire categories of attack vectors simultaneously, not just individual vulnerabilities, and the effect compounds over time: a service that is disabled today cannot be exploited tomorrow, cannot develop new vulnerabilities next year, and cannot become a lateral movement path the year after.


